












DATA LAKE ANALYTICS SOLUTION
Unlock Real-Time Analytics from Your Data Lake with Qlik's Analytics Solution
Drive business intelligence from data lakes with Qlik's analytics solution that analyzes raw, structured, and unstructured data in real time with governed, scalable pipelines.

Transform raw data in your lake into actionable insights
Unlock the full potential of your data lake investments with advanced analytics capabilities that turn raw data into business-ready insights without data movement.
Analyze structured, semi-structured & unstructured data in place
Process diverse data types directly within your data lake environment without requiring costly data movement or complex ETL processes.
Run analytics and ML directly on your lakehouse environment
Execute advanced analytics and machine learning workloads directly on lakehouse architecture for faster insights and reduced infrastructure costs.
Scale analytics without data movement or duplication
Analyze data at scale within your existing lake infrastructure while maintaining performance and eliminating expensive data duplication across systems.
How does Qlik's data lake analytics solution work?
Step 1 - Ingest and organize data using automated lakehouse pipelines
Step 2 - Transform, cleanse & catalog data in analytics-friendly zones
Step 3 - Process analytics queries in real time on raw and refined zones
Why choose Qlik for data lake analytics?
Enterprise-grade capabilities designed for lakehouse analytics
Automated pipeline creation with Qlik Compose for lakehouses
Streamline data lake operations with automated pipeline creation, schema evolution, and data organization that eliminates manual configuration and reduces time-to-insight.

End-to-end governance, lineage & catalog integration
Maintain comprehensive control over data lake assets with automated governance, lineage tracking, and integrated catalog capabilities that ensure trust and compliance.

Real-time CDC-based ingestion for fresh insights
Keep analytics current with real-time change data capture and streaming ingestion that ensures your lake analytics reflect the latest business operations.

Built for analysts, data engineers, and BI teams on analytics-ready infrastructure
Provide specialized tools for technical teams while enabling business users to access and analyze lake data through familiar analytics interfaces and self-service capabilities.

Proven cost savings and performance gains with AI‑optimized lakehouses
Join organizations achieving significant cost reductions and performance improvements through AI-optimized lakehouse architectures and intelligent query processing.
Key capabilities of Qlik's data lake analytics solution
Comprehensive lakehouse analytics capabilities for enterprise requirements
Real-time change data capture and high-throughput ingestion
Ingest data continuously from operational systems with real-time change data capture and high-throughput processing that keeps analytics current.
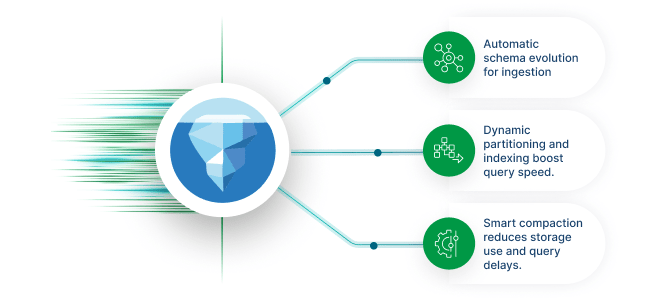
Automatic schema evolution and multi-zone lakehouse pipelines
Handle evolving data schemas automatically while organizing data into bronze, silver, and gold zones for optimized analytics performance and governance.
AI-driven Iceberg optimization for faster queries and lower costs
Optimize query performance and reduce storage costs with AI-driven Apache Iceberg optimization that automatically tunes data organization and indexing.
Integrated metadata, data quality & governance workflow
Maintain comprehensive data governance with integrated metadata management, automated quality monitoring, and governance workflows across lake zones.
Support for multiple query engines (Spark, Athena, Trino)
Analyze data using your preferred query engine with native support for Apache Spark, Amazon Athena, Trino, and other popular analytics engines.
Scalable architecture built on Apache Iceberg lakehouse design
Leverage modern lakehouse architecture built on Apache Iceberg for ACID transactions, time travel capabilities, and schema evolution without data migration.
Trusted by leading enterprises worldwide
We needed to consolidate data in one place, from heterogeneous sources, updated in almost real-time. That’s what Qlik enables for us.
Connect to 500+ data sources with Qlik’s analytics integrations
SAP
Adobe
IBM

AWS

MySQL

Jira

Azure
MS SQL

Apache

Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
Oracle
Salesforce
Workday
Apache Iceberg

CircleCI

Zendesk

Snowflake

Databricks


OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Resources to help you succeed with data lake modernization



Data lake analytics FAQs
Our platform automatically organizes data into bronze (raw), silver (cleaned), and gold (business-ready) zones while enabling cross-zone analytics that can query data across all zones for comprehensive insights.
We provide native integration with Apache Spark, Amazon Athena, Trino, Presto, and other popular query engines, plus compatibility with leading BI tools, data science platforms, and machine learning frameworks.
Our AI algorithms continuously optimize data layout, partitioning, indexing, and query execution plans using Apache Iceberg features, typically resulting in 3-10x faster queries and 30-50% storage cost reduction.
Yes, our platform supports running ML workloads directly on lake data using popular frameworks like Spark MLlib, scikit-learn, and TensorFlow without requiring data movement to separate compute environments.