













DATA ENGINEERING SOLUTIONS
Build Enterprise-Scale Pipelines with Qlik's Data Engineering Solutions
Accelerate your data lifecycle with Qlik's data engineering solutions. Architect scalable pipelines, transform data efficiently, and ensure analytics-ready delivery across cloud and on-premises environments.

Enable efficient, scalable data workflows for modern analytics
Transform raw data into trusted assets with enterprise-grade data engineering that orchestrates, automates, and governs your entire data pipeline infrastructure.
Orchestrate data pipelines across your architecture
Design and deploy multi-stage data pipelines that seamlessly move and process data across hybrid cloud, on-premises, and edge environments with automated orchestration.
Automate data transformations and orchestration
Implement sophisticated ETL/ELT workflows with low-code tools that accelerate development while maintaining the flexibility developers need for complex transformations.
Deliver clean, analytics-ready data with confidence
Ensure data quality and consistency throughout your pipelines with built-in validation, cleansing, and governance controls that prepare data for immediate analytical use.
How do Qlik's data engineering solutions work?
Step 1 - Ingest data from diverse systems seamlessly
Step 2 - Process, cleanse, and transform data efficiently
Step 3 - Orchestrate multi-stage pipelines with automation
Step 4 - Deliver and govern data for analytics access

Why Qlik data engineering solutions?
Enterprise-grade capabilities designed for scalable data engineering

Enterprise-grade governance and data lineage controls
Track data from source to destination with comprehensive lineage visualization, impact analysis, and audit trails that ensure compliance and enable confident troubleshooting.

Scalable across cloud, hybrid, and on-premises deployments
Deploy pipelines wherever your data lives with consistent tooling across AWS, Azure, GCP, on-premises infrastructure, and hybrid architectures without vendor lock-in.
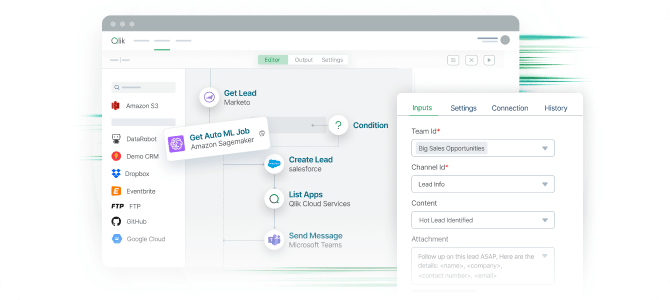
Low-code workflow design for speed and flexibility
Accelerate pipeline development with visual design tools while maintaining the ability to inject custom code for complex transformation logic when needed.
Built for data engineers, architects, and analysts
Serve diverse skill levels with interfaces tailored to each role, from visual builders for analysts to code-first environments for experienced data engineers.

Proven performance in large-scale data workloads
Handle enterprise volumes with optimized execution engines that process terabytes of data efficiently through intelligent parallelization and resource management.
Key capabilities of Qlik's data engineering platform
Comprehensive engineering capabilities for enterprise data pipelines
Real-time and batch data ingestion
Capture data changes as they happen with CDC technology or schedule bulk loads, providing flexibility to match each source's characteristics and requirements.
Automated ETL/ELT pipelines with drag-and-drop
Build sophisticated transformation workflows visually while the platform generates optimized execution code, reducing development time without sacrificing performance.
Built-in orchestration and scheduling tools
Coordinate complex pipeline dependencies with visual workflow builders, time-based triggers, and event-driven execution that adapts to changing data availability.
Data lineage, monitoring, and metadata management
Understand data relationships end-to-end with automatic lineage capture, comprehensive metadata catalogs, and real-time pipeline monitoring dashboards.
Scalable execution across cloud and edge infrastructure
Deploy processing engines wherever performance demands, from centralized cloud clusters to distributed edge locations, with unified management and monitoring.
Enterprise-grade security, permissions, and auditing
Protect sensitive data with role-based access controls, encrypted data movement, and detailed audit logs that satisfy compliance requirements across industries.
Trusted by leading enterprises worldwide
What our customers say
We needed to consolidate data in one place, from heterogeneous sources, updated in almost real-time. That’s what Qlik enables for us.
Connect to 500+ data sources with Qlik’s analytics integrations
SAP
Adobe
IBM

AWS

MySQL

Jira

Azure
MS SQL

Apache

Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
SAP
Adobe
IBM
AWS
MySQL
Jira
Azure
MS SQL
Apache
Mongo DB
Oracle
Salesforce
Workday
Apache Iceberg

CircleCI

Zendesk

Snowflake

Databricks


OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Oracle
Salesforce
Workday
Apache Iceberg
CircleCI
Zendesk
Snowflake
Databricks
OpenAI
Intuit
Resources to help you succeed with data engineering



Data engineering solutions FAQs
Data engineering software supports 500+ connectors including relational databases, NoSQL stores, cloud applications, streaming platforms, file systems, and APIs, with both pre-built and custom connector options.
We support both processing patterns seamlessly—real-time pipelines use change data capture for continuous ingestion while batch pipelines handle scheduled bulk loads, with the ability to mix both in unified workflows.
Yes, our platform supports both visual low-code development and full code-based pipeline creation, allowing data engineers to choose the approach that matches their requirements and preferences.
We provide built-in data quality rules, validation checks, anomaly detection, and profiling capabilities that monitor data throughout the pipeline with configurable alerts and automated remediation options.