











Data Integration
Supercharging Qlik Open Lakehouse: Now Streaming, Trusted, Open, and AI-Ready


Earlier this year at Qlik Connect, we introduced Qlik Open Lakehouse, a fully managed, Apache Iceberg–based platform designed to make it easy and cost-effective for organizations to ingest, optimize, and manage data in open lakehouse architectures. And the first version of Qlik Open Lakehouse is generally available as of Sept 2025.
Today, at AWS re:Invent 2025, we’re excited to unveil the next generation capabilities in Qlik Open Lakehouse — a major leap forward that delivers on highly anticipated features including real-time streaming ingestion, on-the-fly transformations, built-in data quality and governance, and expanded ecosystem integrations.
This launch transforms Qlik Open Lakehouse into a complete foundation for AI, analytics, and operational intelligence — bringing openness, performance, and trust together like never before.
Streaming Ingestion: Real-Time Data, Directly into Iceberg
In today’s AI-driven world, real-time data is no longer optional — it’s foundational.
With Qlik Open Lakehouse, you can already land real-time CDC and batch data ingestion from hundreds of sources (databases, SaaS apps, SAP, mainframes and more) directly into Iceberg tables, with just a few clicks.
Today, we’re introducing high-throughput streaming ingestion for Apache Iceberg, enabling organizations to ingest millions of events per second from streaming sources like Apache Kafka, Amazon Kinesis, and Amazon S3 — directly into Iceberg tables using Qlik Open Lakehouse, without the need for data warehouse for ingestion.
This means you can now continuously collect and query petabytes of real-time data from web and mobile apps, IoT devices, logs, and more — enabling use cases like cybersecurity analytics, IoT monitoring, predictive maintenance, and live AI model training – all with an open, flexible, and interoperable platform.
And it’s cost-efficient by design. Qlik Open Lakehouse leverages cost-effective Amazon EC2 Spot instances with auto-healing, cutting ingestion costs by up to 70-90%, that can amount to millions of dollars in savings. Check out the latest benchmarks comparing ingestion costs and performance for Qlik Open Lakehouse.
More importantly, Qlik Open Lakehouse automatically evolves schemas, optimizes files, and recovers from failures, so you don’t need to. It automatically adapts to evolving schema, even nested ones, to ensure consistent and reliable processing of real-time events.
Here’s a sneak peek at our latest demo showcasing streaming ingestion into Iceberg from Amazon Kinesis.

Streaming Transformations: Shape Data as It Flows
Real-time ingestion is only the beginning. With streaming transformations, you can now cleanse, combine, and reshape data as it flows into your lakehouse — without waiting for complex, hand-coded batch jobs or loading it into a warehouse.
Through a visual, no-code interface, data teams can define transformations such as cleaning, filtering, standardization, un-nesting, flattening, and masking — all applied in-stream, with schema evolution handled automatically.
The result: AI- and analytics-ready data within minutes, not hours or days.
It empowers teams to curate, shape data and resolve data quality and freshness, in real time closer to the source — before they impact end users.
And thanks to Qlik’s cost-optimized compute engine (based on EC2 Spot instances), you get real-time transformation at one-third the cost of traditional approaches — with auto-scaling, failover, and built-in reliability.
Expanded Iceberg Ecosystem: Interoperable by Design
Qlik Open Lakehouse is built for openness. And with this launch, we’re expanding that interoperability even further.
We’re excited to introduce three key ecosystem integrations that make our open lakehouse architecture even more powerful:
Support for Snowflake Open Catalog – We’re adding support for Snowflake Open Catalog and expanding beyond AWS Glue Catalog that is currently available, giving customers greater choice in Iceberg catalogs and enabling seamless data discovery and governance across environments. This integration significantly expands Qlik’s interoperability with the growing Iceberg ecosystem, providing customers the freedom to build modern lakehouses on their own terms — whether they prefer AWS-native services or Snowflake’s cloud-native environment.
Zero-copy mirroring to Databricks and Amazon Redshift – Qlik already enables zero-copy mirroring into Snowflake, allowing users to create external tables and run queries and downstream transformations in Snowflake without duplicating data—preserving performance while reducing costs. Now, we're expanding this powerful capability to include mirroring to Databricks and Amazon Redshift as well, allowing teams to query and transform Iceberg data across multiple platforms without the duplication or the costs.
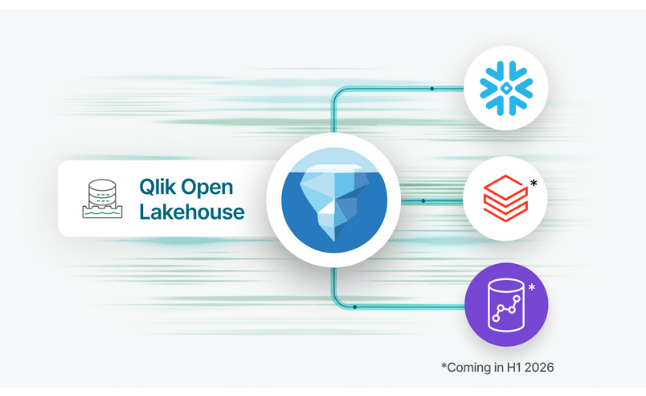
Enhanced Apache Spark integration – We are adding enhanced support for Apache Spark in Qlik Open Lakehouse enabling any Spark-based engine to directly access up-to-date Iceberg data for large-scale analytics, AI, and machine learning workloads.
Together, these integrations deliver a truly open, flexible, and multi-engine lakehouse experience—empowering data teams to eliminate silos, minimize duplication, and accelerate time-to-insight.
End-to-End Data Quality and Governance
Open doesn’t have to mean ungoverned. With Qlik Open Lakehouse we’re now bringing Qlik Talend’s trusted data quality and governance capabilities directly into Open Lakehouse and the Iceberg environment as well.
This brings forth Qlik’s key capabilities including end-to-end data lineage, validation rules, semantic types, and Qlik Trust Score™, ensuring every dataset within your open lakehouse is accurate, traceable, and AI-ready. Users can monitor how data flows and transforms across Iceberg tables and mirrored Snowflake environments, gaining complete visibility and confidence in their data pipelines.
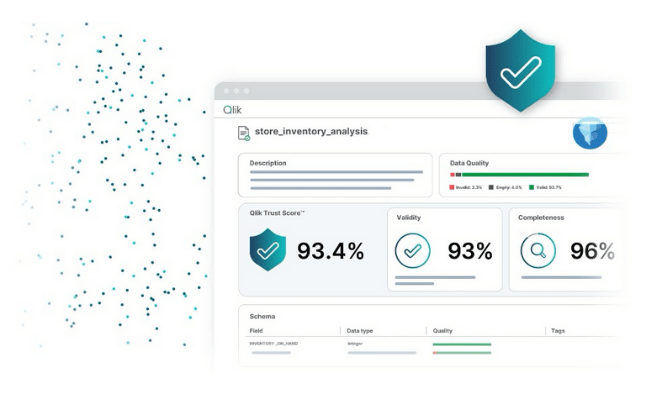
At scale, data quality validation rules can run flexibly—either within Qlik’s managed lakehouse environment or directly inside the warehouse—delivering assurance exactly where it matters most. Semantic types establish consistent meaning and context across diverse datasets, standardizing how information is interpreted across the enterprise.
And with Qlik Trust Score™ and Qlik Trust Score™ for AI, teams can now quantify data readiness for analytics and machine learning, even with data in Iceberg tables —ensuring the insights they act on are truly reliable.
With Qlik Open Lakehouse, openness meets governance—empowering organizations to innovate with data they can trust.
New Benchmarks: Qlik Open Lakehouse
Of course, none of this matters unless it translates into real cost savings and meaningful business outcomes for our customers.
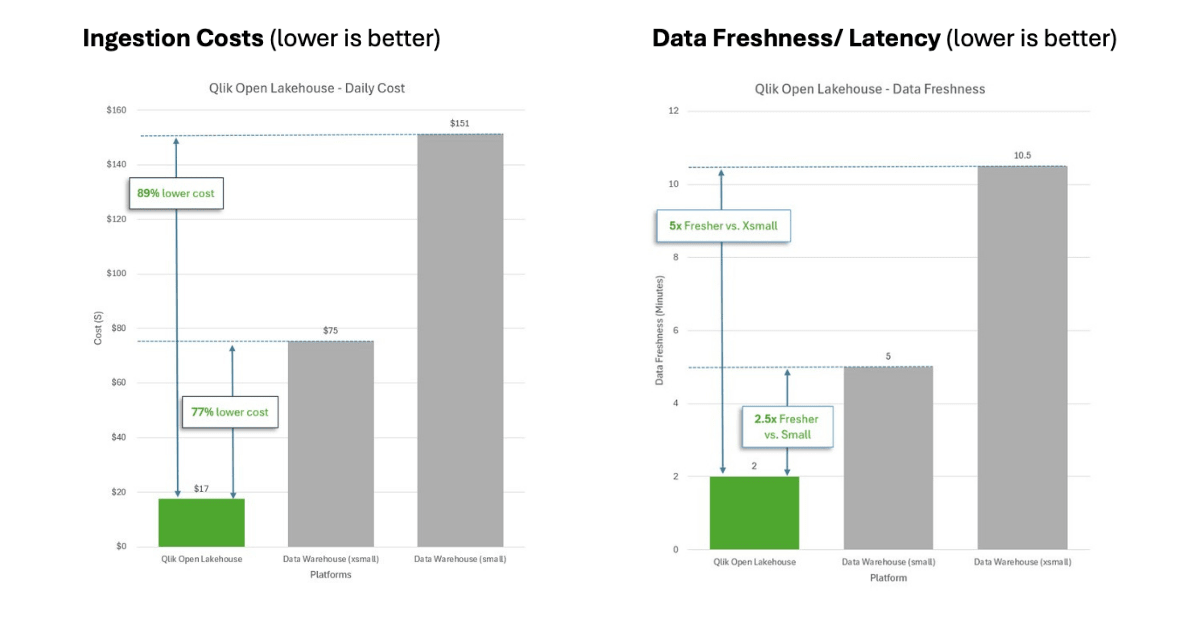
To put that to test, we recently conducted a benchmark study, comparing ingestion costs and performance of Qlik Open Lakehouse to that of a Cloud Data Warehouse while trying to simulate a real-life customer scenario.
Qlik Open Lakehouse with Iceberg delivered orders of magnitude more value for customers, offering approximately 77-89% lower costs and compute burn, while delivering 2.5-5x more data freshness compared to that of a Data warehouse managed Iceberg offering or a native Data warehouse for a similar configuration. You can learn more about the benchmarking test, and results here: Benchmarking Ingestion Costs and Performance of Qlik Open Lakehouse Vs a Data Warehouse
Why All of this Matters
Enterprises today are building for AI and real-time insights, using flexible, and open architectures. But getting there requires rethinking data pipelines, data quality, governance, and cost efficiency.
Qlik Open Lakehouse provides a unified, open, and governed foundation that:
Streams, transforms, and optimizes data in real time
Interoperates seamlessly across ecosystems like AWS, Snowflake, Databricks, and more
Reduces infrastructure and compute spend for ingestion by up to 70-90%, and
Delivers governed, trusted, and analytics-ready data at scale
This is the next evolution of open lakehouses — and it’s built for the future of AI and analytics. With Qlik Open Lakehouse, your data is always accessible, interoperable, and future-ready—no lock-in, no compromise.
Build once, use anywhere — that’s the power of open lakehouse architecture.
Get Started
Qlik Open Lakehouse is already generally available and the key new capabilities that we announced today will become generally availablein Q1 of 2026with expanded features rolling out through the first half of 2026.
Learn more about how Qlik is redefining what’s possible with open, real-time, and trusted data for the modern enterprise.
In this article:
Data Integration