











Benchmarking Ingestion Costs and Performance of Qlik Open Lakehouse Vs a Data Warehouse


Introduction
As the demand for data to power AI models and real-time decision making continues to grow, organizations are increasingly looking for ways to simplify and optimize the ways to ingest, and process fresh data within the enterprise. On average, organizations allocate 20–50% of their annual data warehouse spend on compute for data ingestion, amounting to millions of dollars in costs for large enterprises.
In this post, we delve into a benchmark study that was conducted recently, comparing ingestion costs and performance for an Iceberg Lakehouse versus a leading Cloud Data Warehouse. In this study, we analyze the throughput, scalability, and cost for ingesting real-time data into Qlik Open Lakehouse (powered by Apache Iceberg) compared to ingestion into a top-tier cloud data warehouse’s managed Iceberg offering or native warehouse offering.
Background and Overview
Iceberg-based data lakehouses offers an open data management architecture that brings together the structure and performance of data warehouses and combines them with the cost-efficiency, openness, flexibility, and scalability of data lakes. Today with the growing demands for real-time insights and AI, data engineers need to evaluate whether to ingest their data directly into their data warehouse, or to consider using a lakehouse, with Apache Iceberg as the open table format, to store, and manage their raw data (bronze layer).
Qlik Open Lakehouse provides a key capability within Qlik Talend Cloud that offers an easy and effortless way for customers to ingest real-time or batch data from diverse sources directly into query-ready Iceberg tables within their AWS Cloud environment. More importantly, it automatically handles compaction and optimization of Iceberg tables to deliver peak performance. Customers can query data with any Iceberg-compatible engine—all while maintaining complete data quality, lineage, and governance. These tables can also be mirrored to a customer’s data warehouse without moving or copying data, enabling downstream transformations and analytics on their preferred platform.
So, organizations utilizing Qlik Talend Cloud can now ingest data directly into Apache Iceberg tables within Qlik Open Lakehouse, in addition to existing options for landing data in data warehouses or data lakes.
This blog post is a summary of a benchmark study that was performed to test the throughput and cost of performing real time data ingestion into Qlik Open Lakehouse with Apache Iceberg, against the same ingestion performed into a leading cloud data warehouse managed Apache Iceberg service.
Benchmark Setup
To provide a repeatable benchmark test, an industry standard TPCC benchmark dataset was selected. This should avoid any bias or abnormality based on the dataset itself and can allow other users the ability to repeat or run a similar test for themselves.
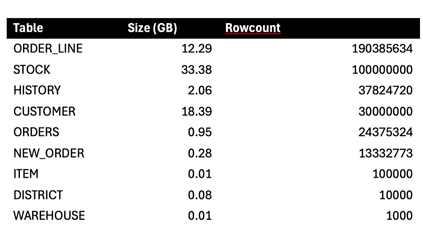
The source data used for this benchmark was created by HammerDB in an Oracle 21c Enterprise Edition database. The TPCC dataset was built using a scale factor of 1000 warehouses. The resulting data set consists of 9 tables, with sizes and row counts at the start of testing shown below (some tables have higher row counts than initially created due to multiple tests being run):
After the initial dataset creation, a PL/SQL script was created to simulate transactional activity against 5 of the source tables. The script simulates INSERT’ing a new order into the ORDERS and NEW_ORDER table, along with its associated items in the ORDER_LINE table. The associated STOCK entries are then updated, and a HISTORY entry is added to reflect the payment details. The scripts used can be found in the linked github repository, should you want to test on your own.
To simulate a real-life high throughput ingestion scenario, the script was configured to run in two parallel jobs and generate between 3000-5000 changes per second across the 5 tables. This script is very similar to the benchmark scenarios provided by HammerDB itself, however it provided additional flexibility to increase the throughput of database activity and also allows for activity generation as a background process.
Ingestion Configuration
In Qlik Talend Cloud, a Data Movement Gateway was installed and configured to handle connecting to the source Oracle system, and two equivalent data pipeline projects were set up.
1. Qlik Open Lakehouse Project
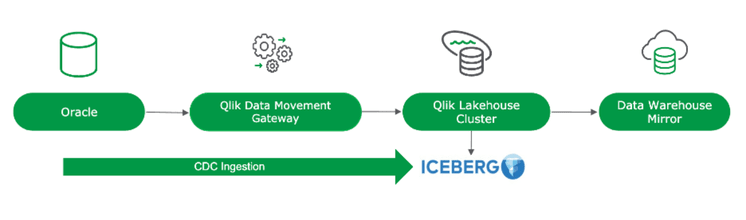
The Qlik Open Lakehouse project ingests data directly into Iceberg tables, leveraging a Lakehouse Compute Cluster that runs in the customers' AWS VPC. Qlik uses cost-efficient Amazon EC2 Spot Instances—with auto-healing and built-in fault tolerance—as the compute engine for data ingestion, eliminating the need to rely on expensive data warehouse resources. The Lakehouse compute clusters can be configured in a way that allows instances to auto scale up (to increase throughput) and down (to conserve costs) in response to fluctuations in data volume changes.
For this benchmark, the Qlik Open Lakehouse cluster was configured to run on the r-family Amazon EC2 Spot Instances of size xlarge (r.xlarge). The cluster was allowed to scale between 1 and 8 instances, using the “low latency” scaling option, designed to maximize throughput. With Qlik Open Lakehouse, ingestion into Iceberg tables loads data every minute, delivering output tables with near real-time freshness. Qlik Open Lakehouse also provides the ability to perform a zero-copy mirroring of the data in Iceberg tables into a data warehouse in near real-time. As a component of the pipeline, the resulting tables were then “mirrored” to the data warehouse, providing the warehouse with the ability to directly query the Qlik Open Lakehouse Iceberg tables, without having to copy the data into the warehouse itself. For the test, the mirror was configured to automatically refresh the Iceberg metadata on every change so that near real-time freshness was available within the warehouse.
2. Data Warehouse Managed Iceberg Project
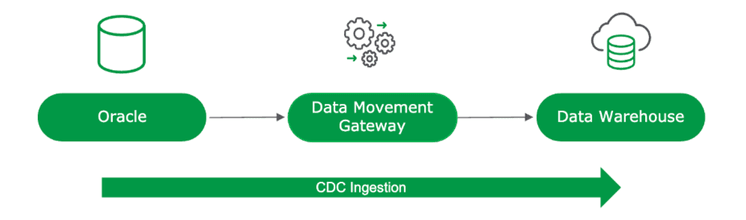
To compare the results, we tested the ingestion costs and performance for ingesting into a data warehouse managed Iceberg offering, utilizing the exact same datasets and configuration. The ingestion layer operates independently of the underlying table format, and so the ingestion costs and performance remain consistent regardless of whether data is written into native data warehouse tables or warehouse managed Iceberg tables.
An equivalent project was created in Qlik Talend Cloud to ingest the same source data into Iceberg tables managed by the data warehouse itself. Ingestion and optimization compute resources were provided by the warehouse directly, and to keep the costs and compute burn to a minimum, we started with the smallest possible warehouse configuration (xsmall). This warehouse was dedicated to ingestion only, with no other activity running against it. To benchmark the impact of real time ingestion, and to compare evenly between scenarios, data was ingested into the warehouse once per minute.
Benchmark Results
Each project began its processing with a full load of each source table. Once the full load was complete, the change script referenced above was started and ran continuously for 24 hours.
Ingestion into Qlik Open Lakehouse: The Qlik Open Lakehouse compute cluster stabilized at 3-4 compute instances (of size r.xlarge) and provided data freshness in the 1-3 minute range. The compute instances averaged 60% utilization during the benchmark, indicating that there was available capacity for increased workloads. During testing, the EC2 spot pricing for r7i.xlarge instances was $0.112 per hour in the us-east-1 region, with the overall cluster compute utilization cost over 24 hours totaling ($0.112 * 4 * 24) = $10.75. To run the Qlik Open Lakehouse, a Network Integration EC2 instance is also required (one per deployment). This instance runs an on-demand instance of size r7i.xlarge and has a price of $0.265 per hour, totaling $6.35 for the day. The Network Integration also runs a Kinesis data stream, with a cost of $0.36. Note, the cost of these Network Integration resources would be shared across all ingestion pipelines. In a real-world deployment where a customer is likely to be running many ingestion pipelines, the proportional cost of these shared resources would be lowered dramatically. Combining the compute services required for the Qlik Open Lakehouse, the total cost of ingestion and optimization comes to $17.46 per day to provide a CDC pipeline with 1-3 minute data freshness, that can be queried by any engine including the data warehouse.
Ingestion into Warehouse-managed Iceberg: To have an apples-to-apples comparison, we tested the cost of ingesting data into the data warehouse managed Iceberg tables using the same ingestion set up with Qlik Talend Cloud. To establish a performance and cost baseline, we started with the smallest available data warehouse configuration: Xtra Small (xsmall). However, it was quickly evident that the ingestion into the warehouse managed Iceberg tables could not deliver the same freshness, as the volume of changes made during the benchmark exceeded the capacity of an xsmall warehouse. While the test was running, significant queueing was observed (see below), which caused data freshness to average in the 6-8 minute range (instead of the 1-3 min range that was observed with Qlik Open Lakehouse), with occasional delays exceeding 15 minutes. The graph below shows the data warehouse utilization during ingestion, with reference to the consistent queuing that was observed.
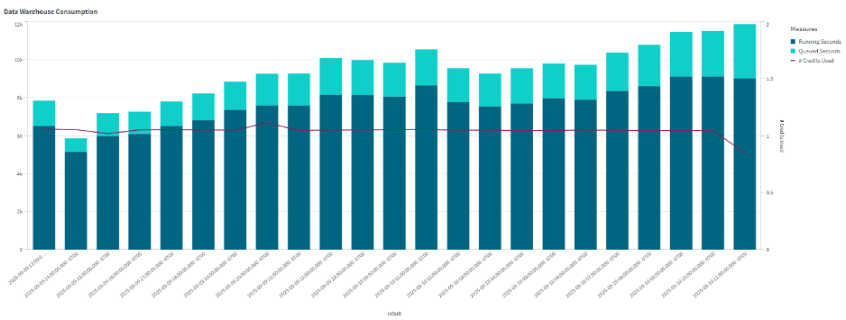
The total credit consumption on the xsmall data warehouse was 24 credits for the warehouse compute, and 1.12 credits for cloud services, totaling 25.12 credits. Based on publicly available pricing metrics, the cost of this ingestion with 25.12 credits, @ $3.0 per credit, would be $75.36 per day with an xsmall configuration. That is approximately 4.5x more expensive to ingest data, compared to the Open Lakehouse option above, even with the reduced 6-15+ minute freshness.
In order to avoid warehouse queueing and to achieve freshness in line with the Qlik Open Lakehouse (of 1-3 minutes), a larger warehouse (sizing of S or M) would be required, which would further drive up this cost /hour significantly. In order to verify this hypothesis, the same test was run on a warehouse of size small (s) for one hour. The testing validated the hypothesis that a size small warehouse delivered better freshness of 4-6 minutes (still 2x worse than Qlik Open Lakehouse), with a credit consumption of 2 per hour (twice the cost of the xsmall warehouse) which would bring the costs per day for this small option to $151.2.
Benchmark Results
The table and charts below provide a summary of the benchmark study results. Lower values correspond to better outcomes for data freshness and cost performance.

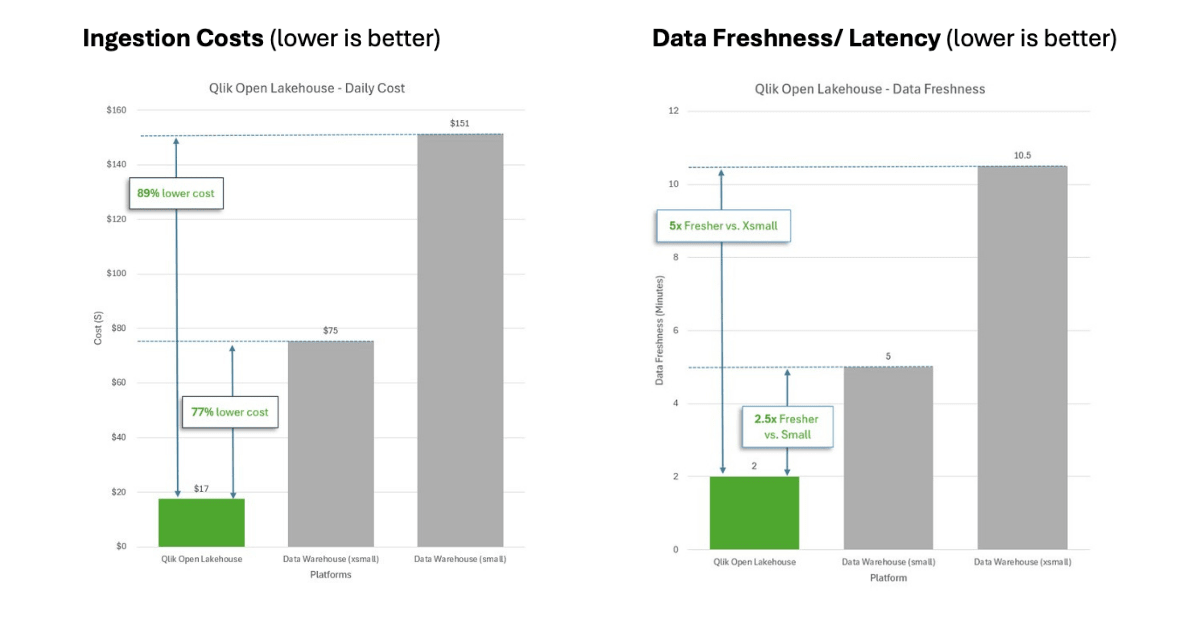
Also, it’s worth mentioning that results are very similar when ingesting native data warehouse tables, as the compute required for ingestion remains the same—whether ingesting the data into a native data warehouse table or a managed Iceberg table.
Summary
Ingestion into Qlik iceberg Open Lakehouse delivers significantly more value for customers, offering approximately 77-89% lower costs and compute burn for ingestion, while delivering 2.5-5x more data freshness compared to that of a Data warehouse managed Iceberg offering or a native Data warehouse for a similar configuration.
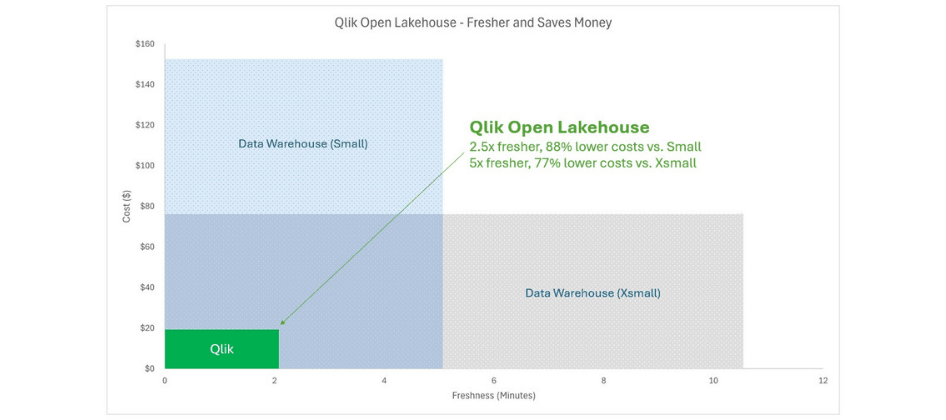
Instead of loading data directly into a data warehouse, customers can quickly unlock value by ingesting terabytes of data into an open architecture using Iceberg tables in Qlik Open Lakehouse, as the bronze layer. From there, the data can be seamlessly mirrored into a data warehouse without copying, in real-time, enabling downstream transformations and refinement to build out the silver and gold layers. More importantly, using Qlik Open Lakehouse and storing data in the open Iceberg table format allows customers to use not only their data warehouse for querying, but open it up to any compatible engine—such as Amazon Athena, Trino, Presto, Apache Spark, or Amazon SageMaker Studio—unlocking seamless access across multiple analytics and AI platforms.
Learn More: