











How Iceberg Powers Data and AI Applications at Apple, Netflix, LinkedIn, and Other Leading Companies


Apache Iceberg is transforming how organizations build and manage their data infrastructure, enabling lakehouse architectures that combine the best of data lakes and data warehouses. In this blog, we look at five real-world implementations demonstrate Iceberg's versatility and the advantages it brings to modern data management challenges.
Learn more about Data Lakehouses
What is Apache Iceberg?
Apache Iceberg is an open table format initially developed by Netflix and open-sourced in 2018. It brings warehouse-like capabilities to data lakes - providing ACID transactions for data consistency, schema evolution for flexibility, and advanced optimization features like partition pruning and time travel. This enables organizations to achieve high-performance analytics on cost-effective object storage while maintaining interoperability across multiple query engines.
Learn more about the basics of Apache Iceberg
5 Industry Examples From Netflix, LinkedIn, and Apple
In recent years, many engineering teams have adopted Iceberg as the foundation for their data lakehouse architectures. This choice is typically motivated by a desire for better performance, scalability, interoperability with data processing frameworks such as Apache Spark, incremental data processing, and compatibility with existing Hive-based data.
The following examples, drawn from public engineering blogs and case studies, showcase how different organizations leverage Apache Iceberg to solve complex data challenges. These are not specific examples from Qlik customers (which you can find here), but merely Iceberg industry use cases that we found interesting, and which have been published elsewhere. We have included links to the original stories as well.
1. Airbnb migrates legacy HDFS to Iceberg on S3
Airbnb’s Data Warehouse (DW) storage was previously migrated from HDFS clusters to Amazon S3 for better stability and scalability. Although the engineering team had continued to optimise the workloads that operate on S3 data, specific characteristics of these workloads introduced limitations that Airbnb’s users regularly encounter.
One of the biggest challenges was the company’s Apache Hive Metastore, which, with an increasing number of partitions, had become a bottleneck, as had the load of partition operations. Airbnb’s engineers added a stage of daily aggregation as a workaround and kept two tables for queries of different time granularities, but this was a time sink.
This motivated the Airbnb team to upgrade its DW infrastructure to a new stack based on Apache Iceberg. From the get-go, this solved many of the company’s challenges:
Iceberg’s partition information is not stored in the Hive Metastore, thus reducing a large amount of load from it.
Iceberg’s tables don’t require S3 listings, which removes the list-after-write consistency requirement and, in turn, eliminates the latency of the list operation.
Iceberg’s spec defines a standardized table schema, guaranteeing consistent behaviour across compute engines.

Source: Airbnb engineering
All in all, Airbnb experienced a 50% compute resource-saving and 40% job elapsed time reduction in its data ingestion framework with Iceberg and other open-source technologies.
>> Read more on Medium
2. LinkedIn scales data ingestion into Hadoop
Professional social media platform LinkedIn ingests data from various sources, including Kafka and Oracle, before bringing it into its Hadoop data lake for subsequent processing.
Apache Gobblin FastIngest is utilised as part of this workflow for data integration, which, at the time of its implementation in 2021, enabled the company to reduce the time it takes to ingest Kafka topics into their HDFS from 45 to just five minutes.
LinkedIn’s Gobblin deployment works alongside Iceberg in the company’s Kafka-to-HDFS pipeline, leveraging its table format to register metadata to guarantee read/write isolation while simultaneously allowing downstream pipelines to consume data on HDFS incrementally.
In production, this pipeline runs as a Gobblin-on-Yarn application that uses Apache Helix to manage a cluster of Gobblin workers that continuously pull data from Kafka and write it in ORC format into LinkedIn’s HDFS. This significantly reduces ingestion latency. The inclusion of Iceberg enables snapshot isolation and incremental processing capabilities in their offline data infrastructure.
>> Read more on LinkedIn Engineering
3. Netflix builds an incremental processing solution to support data accuracy, freshness, and backfill
Netflix has an end-to-end reliance on well-structured and accurate data. However, as the company scales globally, its demand for data and scalable low-latency incremental processing is increasing.
Maestro, the company’s proprietary data workflow orchestration platform, is at the core of Netflix’s data operations. This provides managed workflow-as-a-service to the company’s data platform users. Maestro serves thousands of daily users, including data scientists, content producers, and business analysts across various use cases.
To provide a solution for its growing incremental processing needs, Netflix combined its Maestro platform with Apache Iceberg to achieve incremental change capture in a scalable and lightweight way. This is achieved without copying any data, thereby enhancing reliability and accuracy while simultaneously preventing the unnecessary bloating of compute resource costs.
With this design, Maestro’s users can adopt incremental processing with low effort, mix incremental workflows with existing batch processes, and build new workflows much more efficiently. This bridges gaps for solving a variety of challenges in a more straightforward way, such as dealing with late-arriving data.
>> Read more on the Netflix tech blog
4. Adobe processes billions of events to personalize online experiences
Adobe was one of the earliest adopters of Iceberg in 2020 when it was integrated into the Adobe Experience Platform (AEP) in response to data reliability and scalability challenges.
According to Adobe, managing analytical datasets using Spark at the scale their customers operated had “proven to be a challenge” for reasons including:
Data reliability: A lack of schema enforcement led to type inconsistency and corruption.
Read reliability: Massive tables resulted in slower directories and file listing – O(n), and coarse-grained split planning, leading to inefficient data scans.
Scalability: An overarching dependency on a separate metadata service risked a single point of failure.
Meanwhile, the AEP Data Lake was processing around 1 million batches and 32 billion events per day, which was set to increase dramatically as more Adobe solutions and customers migrated onto AEP in 2021.
Iceberg addressed many of these problems out of the box, and its lightweight design enabled Adobe to implement it without incurring any additional operational overhead and scale it horizontally with its Spark applications.
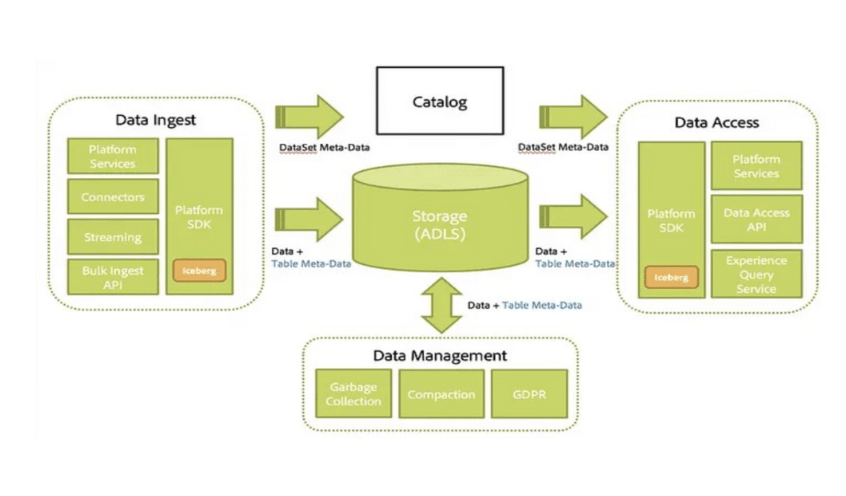
Source: Adobe
>> Read more on the Adobe developer blog
5. Apple scales an Iceberg lakehouse across enterprise data infrastructure
Apple has implemented Apache Iceberg as the foundation for their lakehouse architecture across all divisions, managing tables that range from hundreds of megabytes to many petabytes. According to Russell Spitzer, Engineering Manager at Apple and Apache Iceberg PMC member, the company uses Iceberg for real-time streaming, micro-batches, and traditional ETL workloads at unprecedented scale.
The main challenge Apple faced was handling regulatory compliance requirements like GDPR and DMA, which demand row-level operations rather than partition-level updates. Traditional systems like Hive could only update entire partitions, making compliance operations extremely expensive for sparse updates across massive datasets.
Apple's engineering team developed distributed versions of key Iceberg maintenance procedures and implemented both copy-on-write and merge-on-read capabilities to enable efficient row-level operations. They also created storage partition joins to eliminate expensive shuffle operations during updates, collaborating across both Apache Iceberg and Apache Spark projects.
Following this implementation, maintenance operations that previously took "something like two hours" now complete in "several minutes," while some aggregate queries improved from "over an hour" to "the second range" through enhanced metadata pushdowns that eliminate data file scanning entirely.
>> This use case was presented at the Subsurface conference –read the transcript here.
What are you building with Iceberg?
As we've seen, there has been a shift away from legacy data lake and warehousing solutions towards Apache Iceberg, which offers significant improvements in the form of schema evolution, partitioning, time travel, scalability, and interoperability. Many organizations are building large-scale ingestion architectures around Iceberg and other open-source tools such as Spark.
However, building and managing Iceberg lakehouses at scale presents significant challenges. Organizations need robust solutions for high-throughput ingestion, continuous optimization, data quality/ governance and seamless integration with existing systems. Just a few months ago we announced the acquisition of Upsolver to accelerate our innovation and commitment to Apache Iceberg. Now, by integrating the Upsolver platform into Qlik Talend Cloud, we are excited to launch of Qlik Open Lakehouse – available in private preview.
Qlik Open Lakehouse makes it easy to build, optimize, and scale Apache Iceberg-based data lakehouses. With Qlik Open Lakehouse, you can ingest data from hundreds of sources directly into optimized Iceberg tables with just a few clicks. Our Adaptive Iceberg Optimizer continuously monitors and optimizes your tables to deliver up to 5x better query performance and 50% cost savings compared to self-managed implementations.
By combining the power of Apache Iceberg with Qlik's comprehensive data integration platform, organizations can implement highly optimized lakehouse architectures without the operational complexity typically associated with managing Iceberg at scale.