












Apache Iceberg vs Parquet – File Formats vs Table Formats


Executive Summary:
Apache Iceberg and Apache Parquet are complementary technologies rather than alternative choices.
Parquet is a columnar file format optimized for efficient data storage and compression (similar to CSV or Avro).
Iceberg is a table format that provides an abstraction layer for better data management and universal access (similar to Hudi or Delta Lake).
Together, they form the foundation of modern lakehouse architectures that bring warehouse-like capabilities to cost-effective data lake storage.
File Formats vs Table Formats
When comparing Apache Parquet and Apache Iceberg, we need to first understand the differences between file formats and table formats. Parquet is a file format, whereas Iceberg is a table format.
File formats focus on efficient storage and compression of data. They define how the raw bytes representing records and columns are organized and encoded on disk or in a distributed file system such as Amazon S3.
The Parquet file format has become the de-facto standard for storing data used in analytics workloads. Parquet’s columnar storage provides significant advantages for large-scale analytical querying, including efficient compression, high-performance querying through column-oriented storage, and support for complex data structures.
Table formats provide a logical abstraction on top of the stored data to facilitate organizing, querying and updating. They enable SQL engines to see a collection of files as a table with rows and columns that can be queried and updated transactionally. For example, a table format might contain metadata about underlying data files that allows engines to understand the table's schema, partitions, snapshots and more.
Apache Iceberg is an open-source, high-performance table format designed for large analytical datasets. It provides warehouse-like capabilities such as ACID transactions, schema evolution, and time travel on top of data lake storage, enabling organizations to build scalable, reliable lakehouses with the flexibility to use multiple query engines.
Learn more about Apache Iceberg
The Relationship Between Parquet and Iceberg
Since Iceberg is an open table format, it is not tied to any specific file format. It is designed to work with multiple formats like Parquet, Avro and Orc. An Iceberg table abstracts a collection of data files in object storage or HDFS as a logical table.
Under the hood, the actual table data is still stored in splits of files in the underlying file system – usually in a format like Parquet. Iceberg layers on table management capabilities while still leveraging those underlying file formats. While Parquet handles low-level representation and storage, Iceberg adds table semantics and capabilities like transaction consistency, time travel and schema evolution.
The following diagram is taken from the Iceberg table spec, with our notes in green:
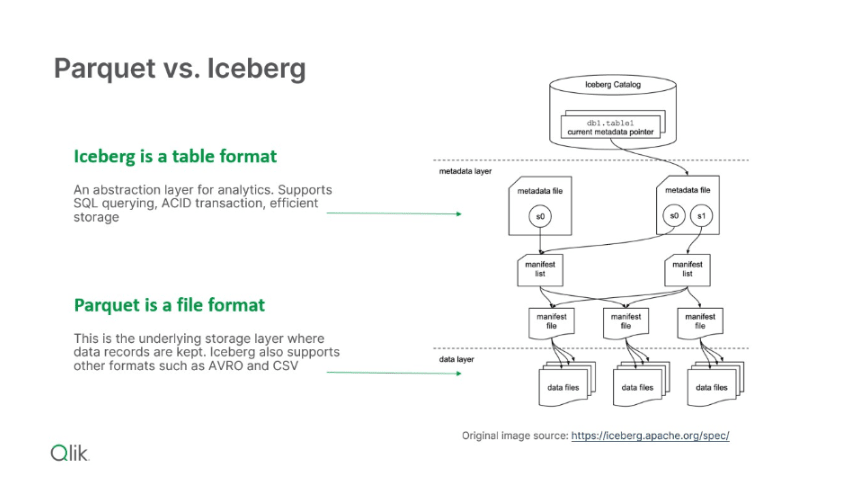
For example, when data is added or updated in an Iceberg table, new Parquet files may be written representing the changes. But from a SQL engine’s point of view, it interacts with the logical Iceberg table abstraction and doesn’t need to reason about the underlying files directly.
Iceberg Improves Parquet by Enabling Ubiquitous Access to Cloud Data
One major motivation behind the development of Iceberg was enabling ubiquitous access to data stored in cloud object stores such as Amazon S3 or Azure Data Lake Storage. Rather than tying data to a specific query engine like Snowflake, Spark or Hive, Iceberg provides a way to manage tables centrally and expose them to multiple processing engines.
For example, a user may choose to use Snowflake or Presto for ad-hoc SQL querying over Iceberg tables, while periodically running ETL batch jobs with Spark that read and write from those same Iceberg tables. Iceberg’s capabilities around time travel, snapshots and transactions facilitate this concurrent access. The goal is avoiding silos and “copies of copies” by allowing many engines to leverage the same storage layer.
Additional Benefits of Combining Iceberg with Parquet:
Enhanced performance: Iceberg's metadata tracking combined with Parquet's columnar storage enables intelligent query planning and partition pruning, which ultimately helps with more efficient data retrieval.
Cost optimization: Parquet's compression efficiency reduces storage costs while Iceberg manages file lifecycle and cleanup automatically. This enables organizations to reduce the amount of data scanned, stored, and processed and lower the total cost of their data operation.
Enterprise reliability: ACID transactions ensure data consistency while supporting operations such as updates and deletes (e.g. for compliance purposes).
Simplified data management: Iceberg handles complex operations such as schema evolution and compaction while preserving Parquet's query optimization benefits and the benefits of vendor-neutral storage.
Multi-engine compatibility: Users can access the same Parquet-based data through different engines without data movement or duplication. This helps to ensure everyone is looking at the same data and reduces the costs and security risks of maintaining multiple copies of the same dataset.
Build High-Performance Lakehouses with Parquet, Iceberg, and Qlik
Qlik Open Lakehouse is a fully managed capability within Qlik Talend Cloud that makes it easy, effortless, and cost-effective to ingest, process, and optimize large amounts of data in Apache Iceberg-based lakehouses on Amazon S3 using Parquet as the underlying storage format.
High-throughput ingestion: Qlik can reliably ingest data from hundreds of sources directly into query-ready Iceberg tables on Amazon S3 with just a few clicks
No-code configuration: Simply point Qlik at your data sources like databases, SaaS applications, SAP, mainframes or CDC event streams, and it will automatically create optimized Iceberg tables ready for analysis
Automated optimization: Qlik's Adaptive Iceberg Optimizer handles schema management, partitioning, compaction, and layout optimization automatically, ensuring your Parquet-based Iceberg tables deliver optimal performance
Multi-engine compatibility: Access your data through any Iceberg-compatible engine including Snowflake, Amazon Athena, Apache Spark, Trino, Presto, and more