













Executive Insights and Trends
Redefining Data Engineering for the Agentic Era
The Future of Data is Here at Qlik Connect 2026


“The data integration landscape is currently undergoing a seismic shift. We are moving away from an era of human-led data pipelines and entering the age of Agentic Data Management. In this new reality, autonomous systems do not just follow static scripts; they reason, plan, and execute entire data lifecycles—from real-time ingestion to self-healing repairs.”
Today, I’m proud to announce a trove of new agentic capabilities for Data Engineers that will redefine traditional workflows and put you at the forefront of innovation. These agentic capabilities come quickly on the heels of our Feb 10th AI announcement and are the first of many data integration and quality-related AI capabilities we plan to release.
Moving From ‘Data Pipeline Plumber’ to ‘Architect of Intent’
For decades, the role of the data engineer has often been compared to a plumber in a video game, who spends intense hours building pipelines that deliver data for analytical, operational, and AI applications. Our mission at Qlik has always been to provide high-productivity pipeline-development solutions, so engineers spend less time rushing around like Mario and more time delivering trustworthy data. However, we’ve recently noticed that generative AI innovations could raise our productivity standards to the next level and transform Data Engineers from simple keyboard commando into architects of intent in a transformation we’re calling Agentic Data Engineering.
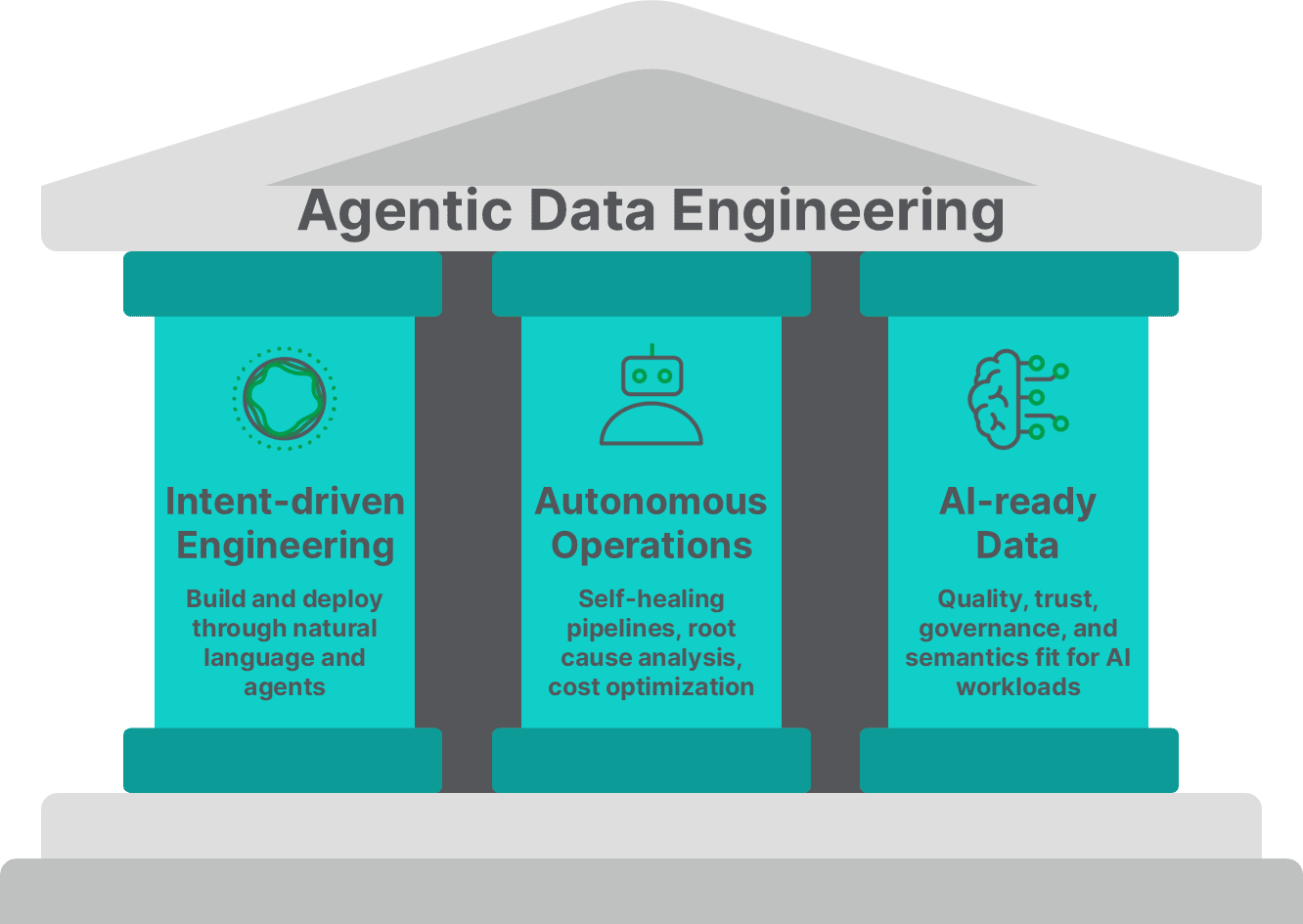
The Three Core Pillars of our Strategy
We define Agentic Data Engineering as “The practice of using and building agentic AI capabilities to deliver trusted data for AI workloads” and our approach is built upon three fundamental pillars, as follows:
1. Intent-driven Engineering (From "How" to "What"): The first pillar is about shifting our focus from the methods of doing things to the desired results. We are transitioning data engineering from the “how” (i.e., "hands-on-keyboards") to the “what we want” (i.e., orchestrating entire pipelines through natural language). Instead of adding components to a canvas or writing complex SQL, data engineers can now describe a desired outcome and let AI agents handle all the heavy lifting.
2. Autonomous Operations (The “Self-healing Grid”): The second pillar focuses on the pipeline controlling infrastructure. While AI agents deliver the flexibility needed for intent-based design, our vision is to provide data engineers with the ultimate control of deterministic processing. Building a pipeline is half the battle. Keeping it alive and reliably running is the other. We foresee a world where the data stack manages itself to ensure reliability by leveraging platform metadata and Agentic AI capabilities. For example, if a pipeline breaks at 3:00 AM, AI agents could perform root cause analysis (RCA) and trigger "healing agents" to minimize downtime, without human intervention. While this goal is mainly aspirational for now, we’re taking many steps to automate and augment our existing monitoring and administration features with AI.
3. AI-ready Data (The Foundation of Agentic Trust): The third pillar focuses on the actual data that Data Engineers deliver to their consumers. It’s undeniable that AI agents and agentic workflows cannot function reliably without verified, high-quality, up-to-the-minute data. Furthermore, there’s a higher possibility of AI applications hallucinating without the right context data and guardrails, all of which introduce risks to your business. Today, our market-leading data quality and data product offerings, including the patented Qlik Trust Score for AI, are mitigating some of those risks by improving the input data for model training and LLM context. Our long-term goal, however, is to develop an Agentic Data Quality, Governance, and Observability ecosystem that proactively reasons and autonomously remediates data issues to ensure decision-making is always based on accurate, timely, and truthful data.
New Agentic Data Engineering Features
With the strategy now clear, the next step is to turn it into something you can easily use. Therefore, we’re introducing a set of new capabilities that make agentic data engineering practical, with features that let you express outcomes in plain language, build and operate pipelines, and raise data trust and quality. Below, we’ll walk through what we’ve announced at Qlik Connect 2026 and how each feature maps back to our three pillars of intent-driven engineering, autonomous operations, and AI-ready data.
Expanding the Qlik Agentic Experience
The first step toward the goal of intent-driven engineering is to extend the Qlik Answers AI assistant to data engineering use cases and to add additional agents to handle the complexities of the modern data lifecycle.
Data Product Agent – Helps users specify, create, maintain, govern, and access high-quality, curated Data Products.
Data Quality Agent – Assists human data stewards in profiling, monitoring, and remediating errors to ensure data remains reliable.
Catalog Agent – Automates the discovery and documentation of assets, allowing users to find context via natural language queries.
Glossary Agent – Automates the definition, governance, and standardization of business terminology across the organization.
Pipeline Agent – This agent automates the creation and deployment of intelligent pipelines that ingest and deliver data to diverse environments. Note. This agent will be released later than the other agents, since it depends on the declarative pipeline feature being released first.
We’re releasing these Agents as together because data engineering and analytics work is iterative: users need to find the right assets (Catalog Agent), speak the same language about what fields mean (Glossary Agent), bundle trusted outputs for consumption (Data Product Agent), and ensure those outputs remain reliable and accurate as data changes (Data Quality Agent). All through a single conversational experience.
We believe this marks the first time an enterprise data integration platform has combined such a comprehensive "Agentic Swarm" to automate data tasks.

Furthermore, this is just the beginning. We plan to embed the same AI assistant experience directly into Talend Studio later this year—so pro-code integration pipeline developers can design, debug, document, and optimize jobs with natural-language guidance, right inside the Talend Studio IDE.
We’re not stopping there. We also can’t ignore the growing ecosystem of third-party coding agents, such as Anthropic’s Claude Code and Microsoft’s GitHub Copilot. We’re embracing those ecosystems with our new declarative pipeline technology, which defines our data pipeline logic as a stable contract and specification for generating, refactoring, and extending pipelines. Now, Data Engineers can chat with their preferred agent coding platform to build data pipelines.
Furthermore, more sophisticated data engineering conversations can be enabled by configuring the coding agent with Qlik’s MCP tools. You can discover the right data sources or assets, generate transformations, automatically create profiling and validation checks, and stream trusted data – without writing a single line of code.
Supporting these copilot ecosystems matters because we’re meeting developers where they already work, embracing enterprise-approved tools, accelerating data delivery, and lowering barriers to adoption.

The last major intent-driven initiative is harnessing LLM functionality within your enterprise processes to improve efficiency. Agentic Routes have enabled AI in Talend integration workflows since early 2025, and this year, we have increased the context memory window to support more complex enterprise scenarios. So instead of treating an LLM as a disconnected chatbot, Agentic Routes lets you orchestrate record flow, choose transformations, enrich data, and trigger downstream actions based on that extended context—while keeping the entire interaction governed, observable, and auditable.

Autonomous Operations
Qlik is uniquely positioned to deliver a self-managing data stack, with many foundational components already in place. At the core is our metadata catalog, which maps every data asset, pipeline dependency, and quality rule across the enterprise. In an agentic world, this metadata becomes the "nervous system" that AI agents use to trace anomalies, understand context, and assess the impact of failures with or without human intervention.
Building on this foundation, we plan to extend pipeline monitoring with goal-based AI infrastructure agents that not only observe problems but also actively resolve them. These agents will perform root cause analysis to identify whether issues stem from schema drift, API changes, or data volume spikes, and then autonomously set resolution goals. Paired with an evolved alerting framework, passive notifications become active, multi-step remediation workflows that only escalate to humans when confidence thresholds aren't met, with every action fully logged for auditability.
The result will be a platform that doesn't just flag what's wrong but also fixes it. I’ll have much more to say in the future as these improvements are developed and released into the market.
AI-ready Data
The features I’ve described so far have focused on improving data engineers’ personal productivity, but the final pillar focuses on the data that Data Engineers deliver to their consumers. We know that AI agents cannot function reliably without verified, high-quality data and can hallucinate without the right context data and guardrails. This is where Agentic Data Stewardship steps in.
Agentic Data Stewardship is the melding of autonomous AI into the data quality process with a "human-in-the-loop" paradigm. When data quality problems surface, autonomous agents proactively identify, profile, and recommend remediations by flagging anomalies, scoring data assets, and proposing corrective actions before a human data steward digs in.
Stewards review, approve, or refine those recommendations, combining the speed and scale of AI with the judgment and accountability of human expertise. The result is data that is systematically prepared, evaluated, and governed to meet the needs of every AI project. Thus, ensuring that when AI agents reason and act, they do so on a foundation of verified, trusted information rather than a patchy context that leads to poor decisions.
Looking ahead
As AI shifts from assisting to acting, data engineers are evolving from pipeline builders into architects of intent, trust, and outcomes. By combining intent‑driven design, autonomous operations, and AI‑ready data, Qlik is helping teams scale their expertise without scaling complexity.
Agentic Data Engineering is the next evolution of the craft, where intent replaces instructions, and intelligence replaces toil. The teams that embrace this ethos won’t just deliver data faster, but fundamentally change how their organizations think, decide, and act. The future of data engineering has arrived, and it’s agentic.
See the Agentic Data Engineering Features in action at the Agentic AI Booth at Qlik Connect 2026.
In this article:
Executive Insights and Trends