











AI
Qlik + Microsoft Fabric Open Mirroring: The Fast Track to Real-Time Data Intelligence


AI needs data at speed
In the AI era – the need for enterprise-wide data—from every operational system—available for instant analytics is real. Microsoft Fabric has fundamentally simplified the modern data estate, centering everything around the flexible, unified power of OneLake. A cornerstone of this platform is Mirroring, a low-latency, low-cost solution designed to break down silos. But for data engineering pioneers, the most exciting development is Open Mirroring. This powerful capability extends the reach of Microsoft Fabric, allowing datato be written directly into a mirrored database, where Fabric handles the complex merging and converts it straight into analytics-ready Delta Lake format.
This is where the power of Qlik Talend® Data Integration & Quality comes in.
The Last Mile Challenge: Complexities of Extracting Data from Heterogeneous Sources
While Microsoft Fabric provides the perfect destination, the most critical challenge remains the "last mile" of data integration: reliably extracting high-volume change data from complex operational systems.
Traditional methods rely on custom code or complex ETL, leading to:
Source System Impact: High-impact queries that slow down mission-critical OLTP applications.
Limited Scope: Inability to handle specialized systems like SAP, Mainframes (DB2 z/OS), or specific cloud database configurations.
Data Drifts: Synchronization issues between the source and target, leading to inconsistent insights.
To truly feed Microsoft Fabric Open Mirroring with the breadth of data your business generates, you need an enterprise-grade Change Data Capture engine built for speed and scale.
Reflecting on Open Mirroring with CDC
Qlik Talend offers best in class low-code solutions for log-based Change Data Capture (CDC) available as client-managed and SaaS solutions to cater for on-premises, cloud and hybrid environments. It is designed specifically to overcome the source-side complexity, making it the perfect complementary engine for Microsoft Fabric Open Mirroring.
Qlik Talend acts as the high-speed bridge, efficiently handling the change data extraction and ensuring it lands perfectly in Microsoft Fabric’s open mirroring landing zone. The data movement starts with Qlik Replicate®.
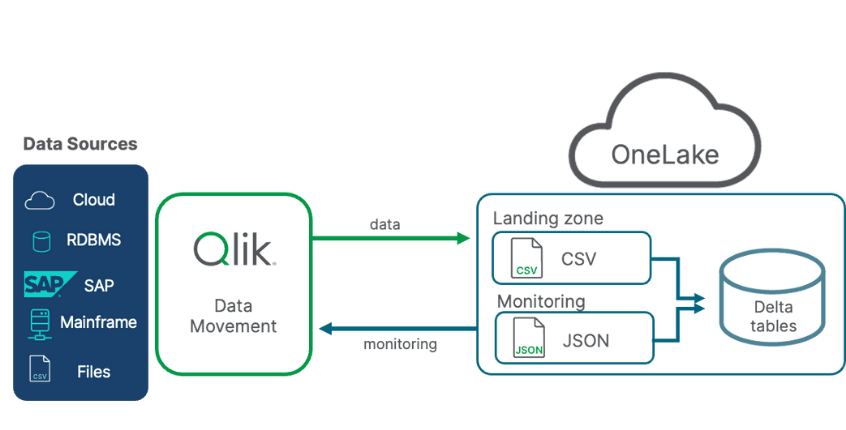
Here’s the power chain:
Qlik Replicate: Continuously monitors mission-critical databases (DB2, Amazon Aurora for Postgres SQL, Maria DB, Teradata, etc.) using low-impact, log-based CDC.
Optimized Data Pipelines: Qlik delivers changes as and when they occur and streams (inserts, updates, deletes) in the specified format directly to the Open Mirroring landing zone URL in OneLake.
Fabric Mirroring Engine: automatically processes this change stream and merges the data into up-to-date, highly performant Delta Lake tables.
The result is a unified, real-time data flow without writing a single line of complex ETL.
From Any Source to Delta Lake: The Power of Openness
Qlik Replicate supports 40+ heterogeneous source systems on the market. Whether your critical inventory data sits in a Mainframe or your core financial records reside in Oracle or SAP, Qlik can capture those changes. By leveraging Qlik, you guarantee that all your operational data can participate in the Microsoft Fabric ecosystem. This combined solution embraces the open standard, delivering truly democratized data access in the Parquet-backed Delta Lake format, ready for all your downstream Microsoft Fabric experiences.
Simplicity and Speed: Automated data pipelines, without the Complexity
The most compelling benefit of combining Qlik with Open Mirroring is the elimination of pipeline complexity, and increased performance. Eastman has seen significant efficiencies with mirroring from their SAP Application DB on Oracle systems.
“Qlik Replicate's Open Mirroring integration has dramatically reduced end-to-end latency from over 10 minutes to under one minute and moved us from daily operational interventions to sustained, long-term stability. This combination has transformed our ability to deliver real-time insights to Microsoft Fabric targets with the reliability and performance our teams require.” – Ben Hobbs, Senior Data Architecture Administrator at Eastman
Qlik automates the creation and management of the CDC stream, while Microsoft Fabric automatically manages the target-side merges and data conversions. You benefit from:
Near Real-Time Data: Log-based CDC ensures data movement is measured in seconds, not hours.
Fully Managed Process: Less manual configuration, maintenance, and monitoring overhead.
Zero-Impact Extraction: Qlik works silently in the background, minimizing latency and risk to your source systems.
Analytics and AI-Ready Data, Instantly Available via Direct Lake
With Qlik Talend and Microsoft Fabric your data is converted into Delta Parquet format in OneLake. This makes it instantly available for use across many use-cases.
Analytics: Leverage high-speed querying via Direct Lake, accessing fresh data without duplication.
Data Science & AI: Use the most current operational data for machine learning models and predictive analytics.
Data Engineering: Seamlessly integrate the mirrored data with other sources in Lakehouses and Warehouses.
Conclusion: Your Unified Data Fabric Starts Now
The convergence of Qlik Replicate's unparalleled CDC capabilities and Microsoft Fabric's revolutionary Open Mirroring architecture provides an unmatched platform for enterprise data modernization. Eliminate brittle, complex pipelines, and start capitalizing on near real-time, unified data.
This functionality will be available in Qlik Talend Cloud soon, stay tuned!