











Bringing Real-Time Streaming to Qlik Open Lakehouse


The appetite for real-time data continues to grow. Across industries, the ability to act on data as it arrives is increasingly central to how leading organizations compete, from IoT and fraud detection to event driven analytics and AI agent architectures. Streaming data is no longer a specialist workload. It is becoming a core requirement.
I am excited to announce that streaming ingestion is generally available in Qlik Open Lakehouse, part of Qlik Talend Cloud.
Built on a strong foundation
Qlik Open Lakehouse was built to give organizations a single, unified platform for ingesting, managing, and optimizing Apache Iceberg-based lakehouses. A December 2025 Nucleus Research study found customers achieving 60 to 70 percent improvements in data ingestion processing costs, query compute cost reductions of 25 to 30 percent with up to 5x faster processing, and 30 to 50 percent less time spent on platform management through automated Iceberg optimization.
Streaming sources extend this proven platform to natively support continuous, high-throughput event data, bringing real-time pipelines into the same environment teams use for batch and CDC workloads today.
"Real-time data isn't a nice-to-have anymore, it's foundational to how modern organizations operate and compete. Streaming ingestion in Qlik Open Lakehouse means our customers can finally run their real-time, batch, and CDC workloads from a single, unified platform, without the complexity or cost that has historically come with it."
What we are releasing
Qlik Open Lakehouse now connects natively to Apache Kafka, Amazon Kinesis, and Amazon S3 as continuous streaming sources. No data movement gateway is required. The Open Lakehouse cluster connects directly to your streaming sources, reducing latency and infrastructure overhead from day one.
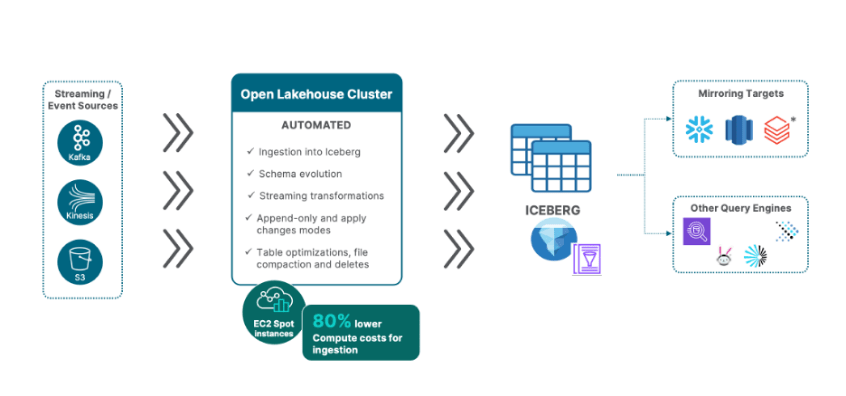
The streaming pipeline is built around two purpose-built task types. The Streaming Landing Task is a lightweight, high-fidelity capture layer that connects to your source, parses incoming events in any supported format, and stages them to your S3 landing area. Schema changes at any level of the event structure are absorbed automatically with no reconfiguration needed. The Streaming Transform Task is where the intelligence sits, handling payload transformation and Iceberg storage together in a single step and giving you full control over how your data is shaped, typed, partitioned, and optimized before it reaches your Iceberg tables.
Five capabilities define the release:
High-throughput ingestion at scale. The pipeline is designed for production streaming volumes, from millions of S3 files to high-frequency Kafka topics, without manual oversight or scaling intervention.
Automatic parsing and transformation. Qlik automatically detects and parses incoming events across JSON, Avro, Parquet, CSV, ORC, and more. Built-in transformation capabilities handle unnesting of complex nested JSON structures, array flattening, filtering, and row-level transformation functions, producing clean, analytics-ready Iceberg tables from the moment data arrives.
Schema evolution, continuously managed. As streaming source schemas evolve, Qlik handles changes automatically and keeps pipelines running. New fields, new nested structures, and new datasets are all managed without manual intervention, with configurable controls over how each type of change is applied downstream.
Automatically optimized Iceberg tables. The Adaptive Iceberg Optimizer works continuously in the background, compacting files, managing partitions, and keeping streaming tables performant without any tuning required.
Two load modes support the full range of streaming use cases. Append Only is purpose-built for high-throughput, event based workloads such as IoT telemetry and clickstream data, where every event is captured at speed and scale. Apply Changes supports upsert behavior when streaming sources are used as event-driven backbones or event hubs for business objects - keeping target iceberg tables in sync with the current state of the object
Streaming sources are available from Qlik Talend Cloud Standard edition and above.
See it at Qlik Connect
Qlik Connect 2026 takes place April 13 to 15 in Kissimmee, FL. Join us to see Qlik Open Lakehouse streaming in action, speak directly with the product team, and get a first look at what is coming next. It is the best opportunity to go deep on the capabilities we are releasing today and understand how they fit into your data strategy.