













Key Benefits
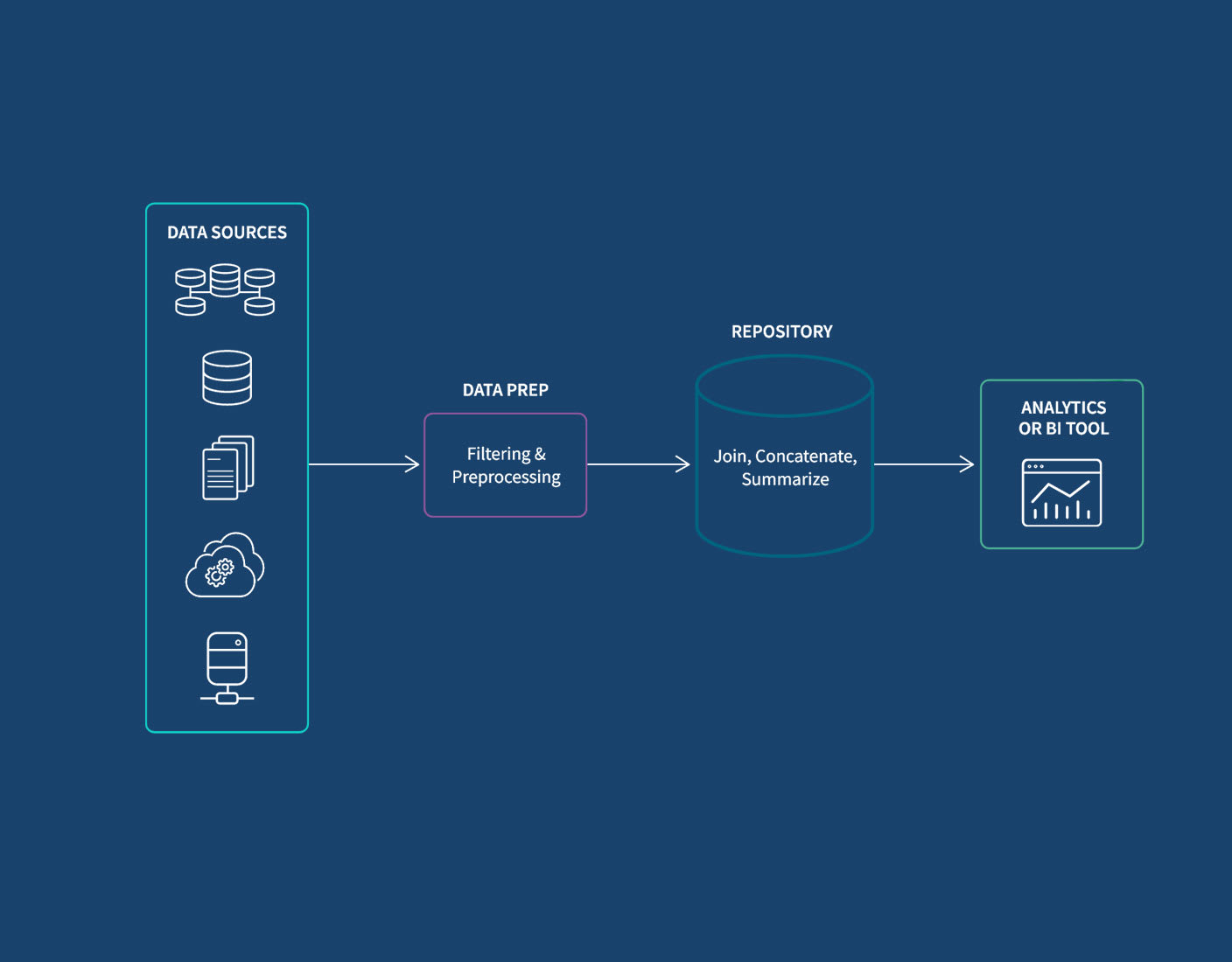
Aggregating data is an important step in transforming raw data into actionable information. The insights you gain can lead to improved performance, greater efficiency, and increased competitiveness. Here are the key benefits:
Improved Decision-Making: Condensed data provides a holistic view of performance metrics and key indicators, helping you make informed decisions based on summarized, actionable insights. It also becomes easier for you to identify overarching trends, outliers, and patterns in visualizations that may not be apparent when working with raw or siloed data.
Reduced Storage and Better Performance: By consolidating data, aggregation minimizes storage needs and reduces the computational resources required for analysis, leading to more efficient operations. This allows for faster querying and reporting, enhancing the speed at which insights can be obtained and acted upon.
Preserved Privacy and Security: Aggregation can help protect sensitive information by summarizing data without revealing individual-level details, thus mitigating privacy risks.
Smoother Integration with BI Tools: Aggregated data is often more compatible with various business intelligence (BI) tools, enabling seamless integration for reporting and analysis purposes.
Foundation for AI Analytics: Aggregated data sets provide a foundation for predictive modeling and forecasting, enabling your organization to plan for the future based on historical trends and patterns.




