














Calculating data value: a practical approach
Today’s savviest business organizations rightfully recognize data as an essential asset. However, measuring data value across the entire data estate is challenging due to its inherent complexity. By breaking data down into smaller units that are business-outcome centric — data products — organizations can more accurately and reliably assess their value.
Data products, which bundle datasets, metadata, and domain logic, offer immense utility — but also present unique valuation complexities.
To measure their value effectively, organizations must assess data products from multiple perspectives, including cost, intrinsic worth, business impact, and market relevance. Ultimately, a practical formula emerges:
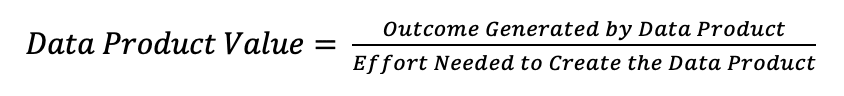
This simple ratio can guide organizations in optimizing their data strategies for maximum ROI. The higher the ratio, the greater the efficiency and effectiveness of leveraging data products.
Not only does this formula deliver a quantifiable value, but it also provides guidance for increasing that value, either by increasing the outcome generated or reducing the creation effort needed.
The numerator: increasing outcomes
The impact of a data product can be defined in many ways, such as user adoption, query frequency, gains in operational efficiency, the number of use cases for which the data product can be leveraged (including AI and machine learning), and the monetary value generated from those use cases. Organizations can enhance these outcomes by improving several factors, including:
Discoverability: Publishing curated data products in a searchable marketplace makes them easier to find and use. For example, a data scientist working on risk modeling can benefit greatly from easily discoverable data products. Whether it’s a flood risk model, hurricane model, or fraud detection model, access to high-quality, curated data products is essential for accelerating model development and model outcomes.
Understandability: Rich metadata — including AI-generated descriptions such as data product descriptions, dataset descriptions, and column level descriptions — helps users grasp the context and relevance of a data product. For instance, the description for a column with temperature readings could indicate whether the temperature is measured in Celsius or Fahrenheit.
Ease of use and reuse: Expanding use cases beyond standard analytics increases adoption, especially as AI use cases become more widespread. For example, data products can feed RAG systems with important contextual information before the system generates a response, improving the response’s accuracy and relevance.
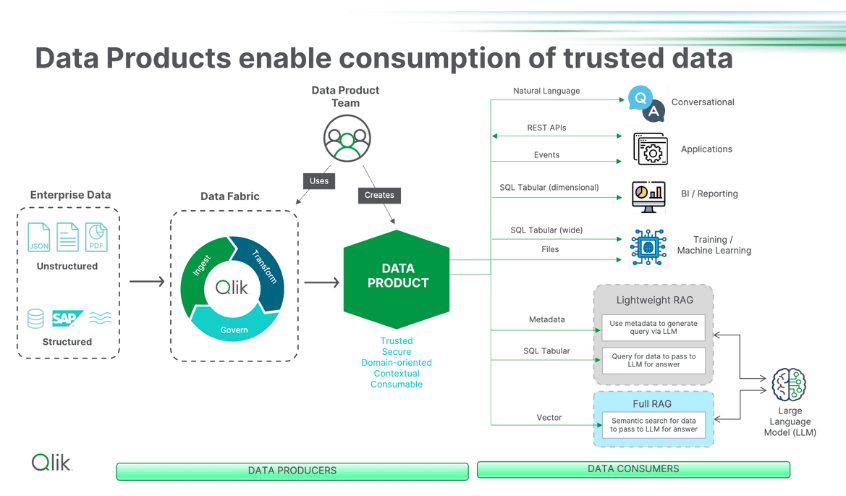
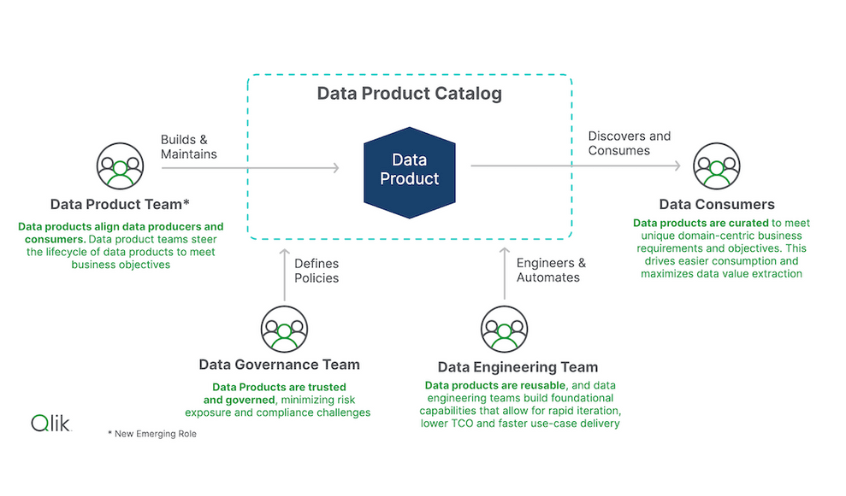
Additionally, data products will be used and reused by different stakeholders, who focus on different components that affect value:
Data Product Managers optimize efficiency and sustainability across all metrics.
Data Stewards prioritize governance, security, and compliance.
Data Engineers focus on reducing development and maintenance efforts.
Business Analysts seek to maximize outcomes aligned with business objectives.
Just as consuming data products in different ways can improve the generated outcome, refining the quality and relevance of data products for individual stakeholders can maximize their value.
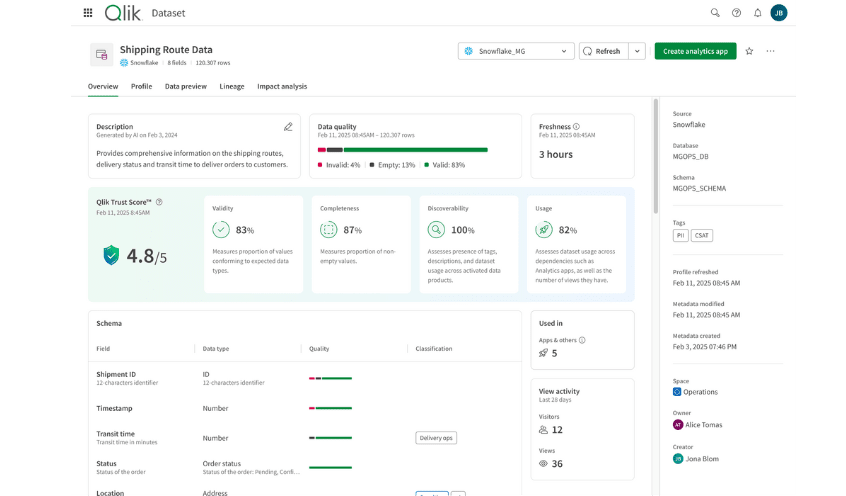
Trust: Transparency in data quality factors fosters confidence and broader utilization. The Qlik Trust Score™ in Qlik Talend Cloud® provides a simple way to view data trustworthiness.
The denominator: reducing effort
Lowering the effort required to create and maintain data products also increases value. Key strategies include:
Optimizing data engineering processes: To ensure the best, most accurate insights, data product managers may be tempted to refreshtheir data products daily. However, if the data product is only used by a handful of users, or is not utilizeddaily by data consumers, the data product can be updated on a less frequent basis to reduce compute costs. If, for instance, the data product is only queried on Fridays, the manager can scale the daily updates back to once a week — perhaps Thursday afternoons — to maintain the data product’s usefulness for users without affecting its reliability.
Optimizing compute costs: Calculating and improving data quality involves computing data fitness across many dimensions, including data accuracy, consistency, completeness, timeliness, uniqueness, and validity — and as such, can be very costly to assess over large datasets in a short time span. What is needed is a flexible approach for organizations to adapt their data quality assessments to their unique data quality needs, whether that means computing quality across all data or choosing a targeted slice. To optimize performance and flexibility, Qlik Talend Cloud supports two data quality processing methods. Pushdown processing, available exclusively for Snowflake and Databricks datasets, triggers quality computations directly within Snowflake or Databricks respectively. This approach ensures efficient, in-data warehouse processing without data movement. Meanwhile, pullup processing, available for all datasets, enables quality computations within Qlik Talend Cloud, enabling broader data quality assessments without relying on external processing resources.
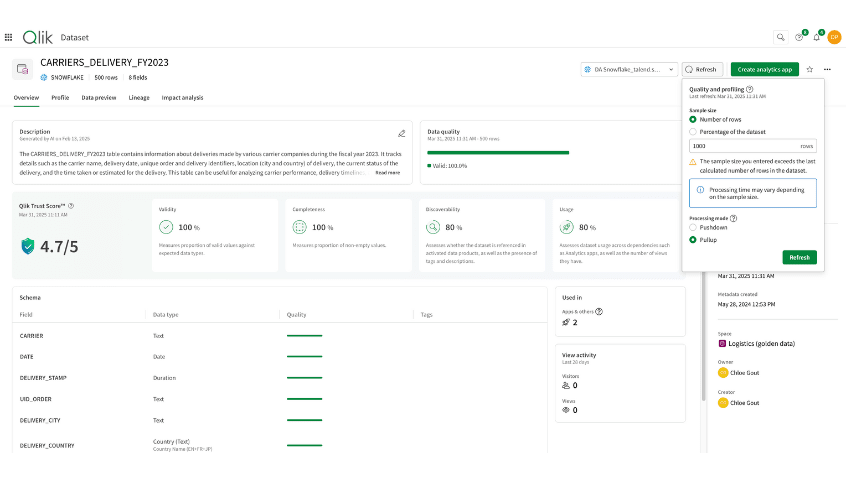
With the Qlik Trust Score, users can also tune certain parameters differently to help balance cost vs. quality expectations.
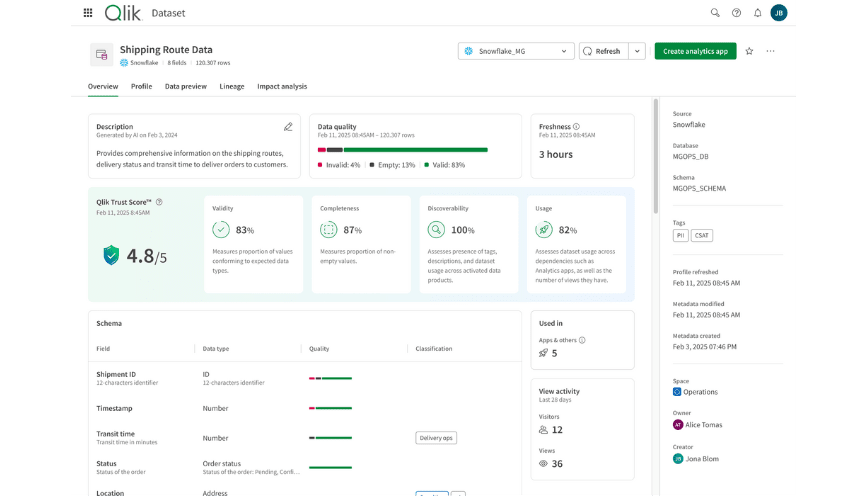
Conclusion
A structured approach to measuring data product value helps organizations make informed investment decisions. By evaluating both cost and impact, businesses can optimize their data strategies for maximum return. Implementing best practices for discoverability, usability, and efficiency ensures data initiatives are purposeful, impactful, and aligned with business goals.
Want to see these principles in action? See for yourself how Qlik Talend Cloud simplifies the creation of high-quality, accessible data products.
This post is part five of the multipart series, Data Product Perspectives. Additional entries are available here.
In this article:
Data Integration