













Data Integration
Database sync: Diving deeper into Qlik and Talend data integration and quality scenarios


A few weeks ago, I wrote a post summarizing "Seven Data Integration and Quality Scenarios for Qlik | Talend," but ever since, folks have asked if I could explain a little deeper. I'm always happy to oblige my reader (you know who you are), so let's start with the first scenario: Database-to-database synchronization.
Database-to-database synchronization
Database sync is the process of keeping two or more databases consistent and up-to-date by exchanging data changes between them. I stated in my overview that database-to-database synchronization is the mainstay use case for Qlik and Talend solutions. However, there are typically four strategic initiatives that companies seek to implement that drive a database sync project. These initiatives are not mutually exclusive, and organizations often implement several projects concurrently. The initiatives are as follows:
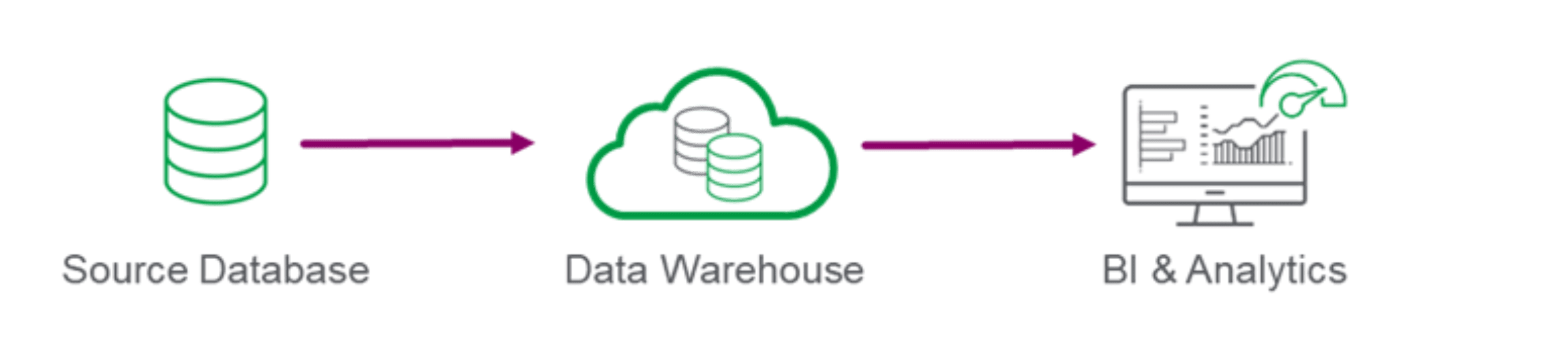
1. Real-time data for reporting and analytics: Many organizations start by building a data infrastructure to improve the efficiency of their analytics and reporting processes. An organization typically begins by creating a central data warehouse in the cloud as its single source of truth. Many popular cloud-based data warehouse platforms exist, including Amazon Redshift, Google BigQuery, Microsoft Azure, Snowflake, and Databricks. However, keeping the warehouse supplied with relevant and accurate data is the key to success regardless of the chosen solution. Not surprisingly, Qlik and Talend has fabulous data integration and quality offerings to make these tasks a breeze. In particular, our market-leading CDC solutions help you quickly replicate data between databases or warehouses to enable more efficient querying and analysis of your data without impacting the performance of the primary database.
2. Real-time data integration: The second scenario for data-to-database synchronization is when organizations seek to re-architect or re-platform existing infrastructure to take advantage of the latest technologies. For example, a company might wish to refactor monolithic applications into discrete micro-services that leverage public cloud infrastructure. In this scenario, a new cloud database is often deployed to act as the definitive data source for the micro-service applications. Consequently, enterprise data sources then replicate data from across the organization to ensure the new cloud database always contains consistent and accurate data. Once again, our market-leading CDC solutions are perfect for this use case.

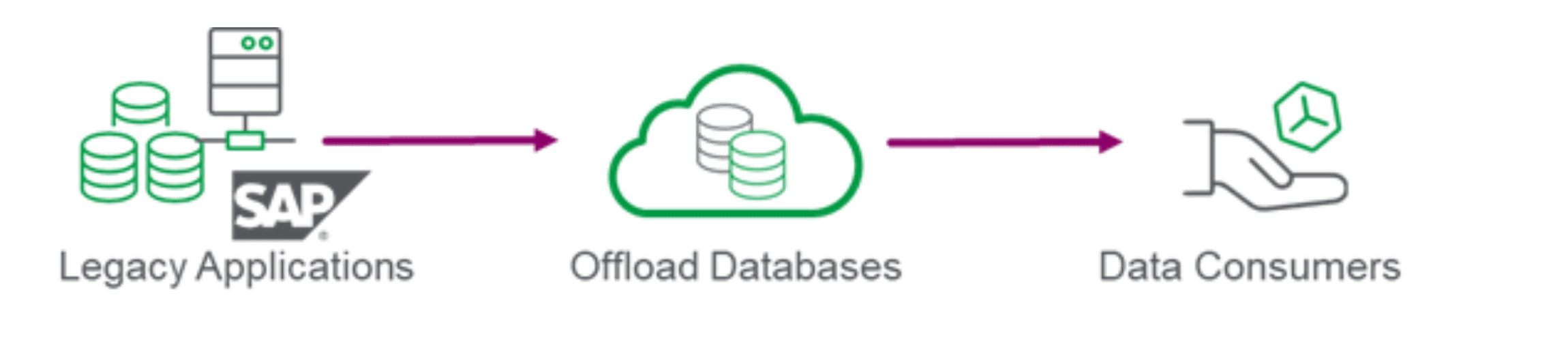
3. Legacy modernization: The third use case for database-to-database synchronization is extremely useful when modernizing legacy applications like SAP, or heritage infrastructures like mainframes. The modernization process keeps the integrity of the original systems intact by offloading data updates to a secondary data store which is then used as the data source for operational analytics or online analytical processing (OLAP). Organizations not only experience an improvement in query performance without upgrading the legacy applications, but also don’t place additional burden on those critical legacy systems from new query workloads. Once again, the best practice is to use an ELT (aka CDC) philosophy to hydrate the secondary data store.
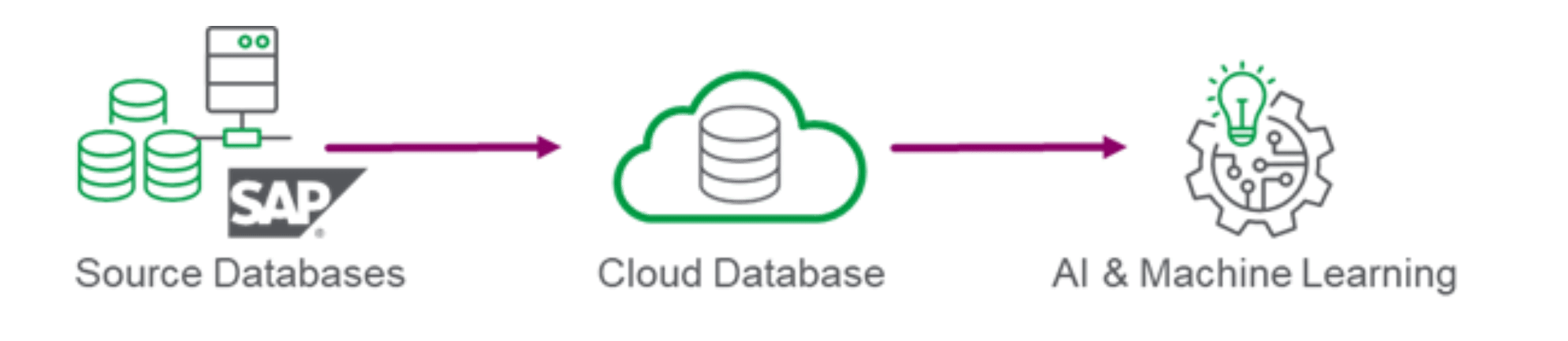
4. Cloud data movement: The final use case is cloud data movement which is sometimes called cloud data migration. Once again, the organization seeks to leverage new cloud technologies for new initiatives such as machine learning (ML). However, ML often requires multiple data sets for training and a live data set for production predictions. Therefore, organizations replicate data from their on-premise data sources to the databases required for ML projects. Again, ELT is typically the preferred approach for data synchronization, but sometimes ETL is used for replicating training data sets since data timeliness is less of a concern.
Choosing between ELT and ETL
One question that frequently crops up when we discuss database-to-database synchronization is when should you use an ELT (extract, load, transform) approach versus ETL (extract, transform, load). My rule of thumb is to consider the importance of a fresh data replica and the type of data destination. If you need the data in near real-time for data warehousing then ELT is preferred. However, if you don’t need an exact copy of your source data and require more curated data sets then batch ETL should be considered.
When tackling the four strategic initiatives for database-to-database synchronization, the combination of Qlik and Talend delivers.
Summary
Database-to-database synchronization is the cornerstone data integration use case for Qlik and Talend solutions. Whether your organization is data loading for analytics, using real-time replication for enterprise integration, or performing micro-batch updates for cloud data movement, we've got you covered!
You can learn more about how the combined portfolio can unlock the power of your data in our webinar, The Art of the Possible: Qlik | Talend in Action.
In this article:
Data Integration