What is ETL?
Extract, Transform, and Load describes the set of processes to extract data from one system, transform it, and then load it into a target repository.
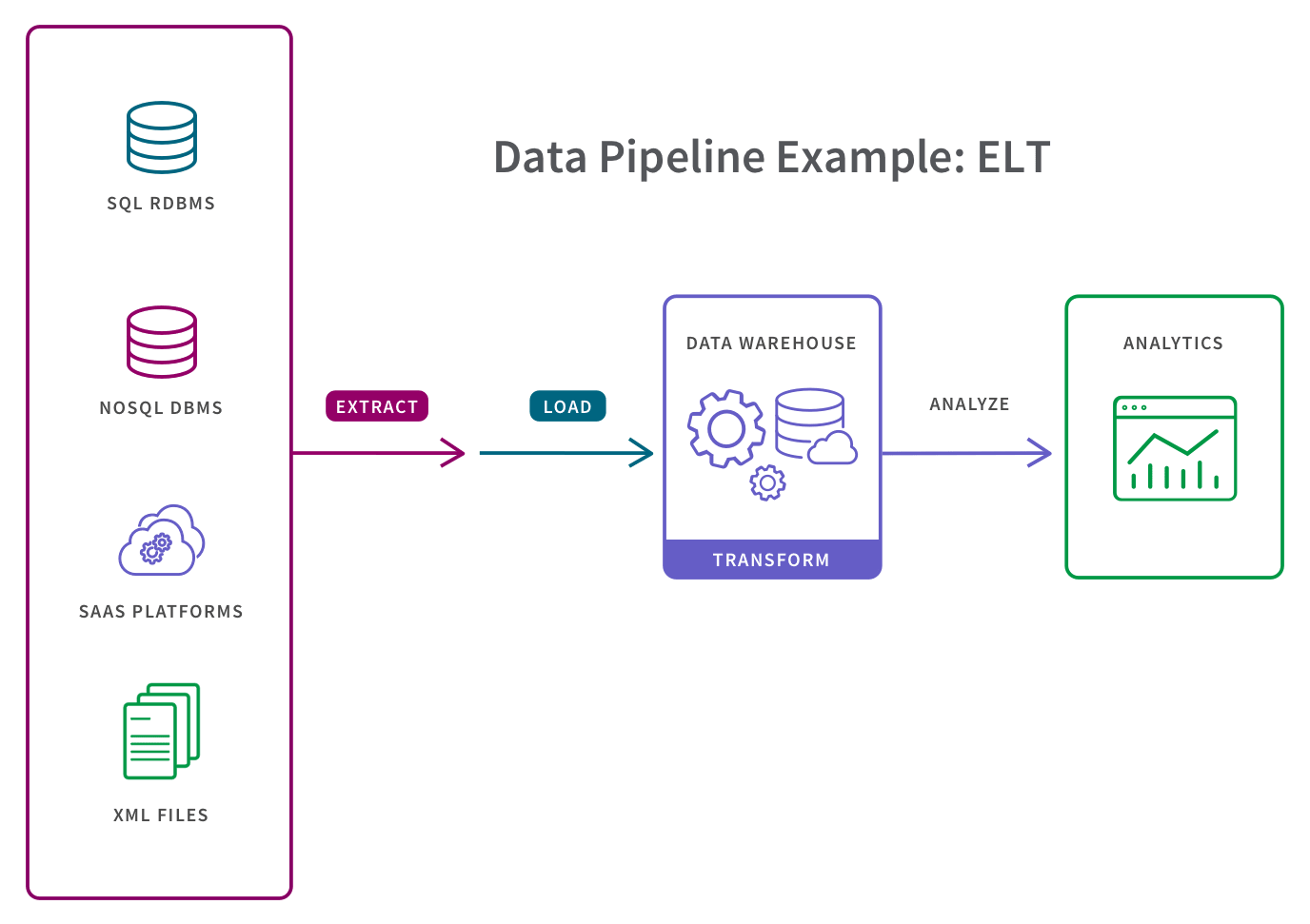
Extract: the process of pulling data from a source such as an SQL or NoSQL database, an XML file or a cloud platform holding data for systems such as marketing tools, CRM systems, or transactional systems.
Transform: the process of converting the format or structure of the data set to match the target system.
Load: the process of placing the data set into the target system which can be a database, data warehouse, an application, such as CRM platform or a cloud data warehouse, data lake or data lakehouse from providers such as Snowflake, Amazon RedShift, and Google BigQuery.
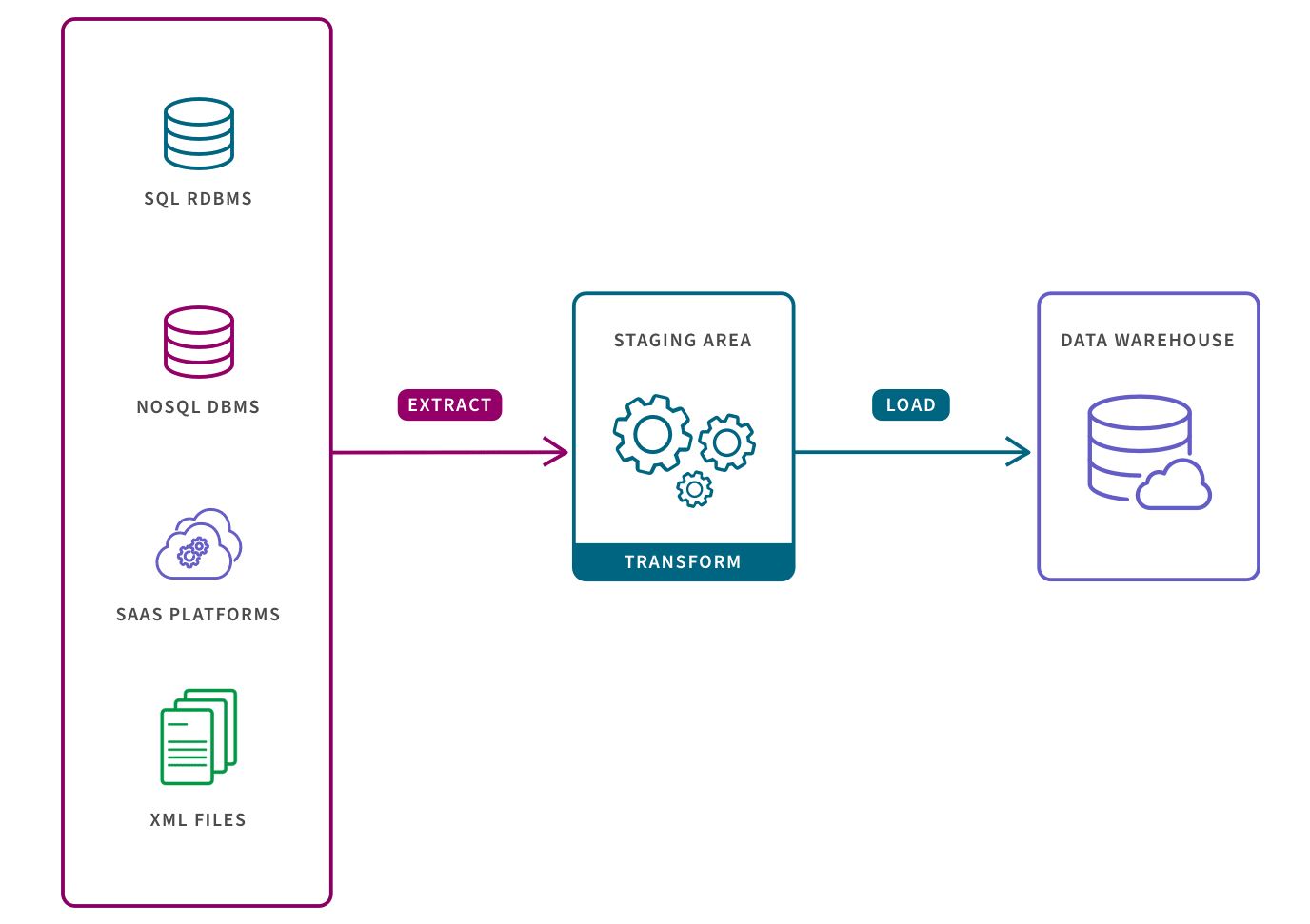
The ETL process is most appropriate for small data sets which require complex transformations. For larger data sets and when timeliness is important, the ELT process is more appropriate (learn more about ETL vs ELT).