







QLIK COMPOSE® FOR DATA LAKES
Le moyen le plus rapide pour créer des data lakes prêts pour l'analytics

Automatisez les pipelines de données prêtes pour l'analytics
Créez des datasets prêts pour l'analytics en automatisant l'ingestion des données, la création de schémas et l'actualisation en continu.

RESSOURCE CLÉ
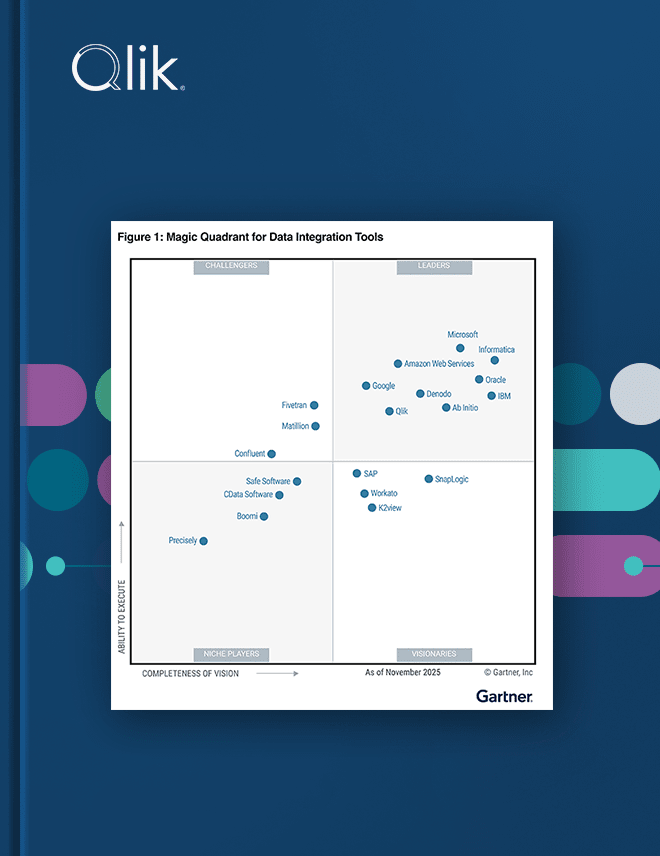
Gartner® Magic Quadrant™ 2025 pour les outils d'intégration de données
Découvrez pourquoi Qlik® figure parmi les leaders du Gartner® Magic Quadrant™ pour les outils d'intégration de données.

Choisissez la facilité pour la structuration et la transformation de vos données
Créez, modélisez et exécutez des pipelines de data lakes dans une interface utilisateur guidée et intuitive.
Générez automatiquement, sans codage manuel, des schémas et des structures de catalogue Hive pour des data stores ODS et HDS.

Optez pour des mises à jour en continu
Ayez la certitude que vos data stores opérationnels (ODS) et historiques (HDS) donnent une image précise de vos systèmes source.
Grâce à la technologie de capture des changements de données (CDC), bénéficiez d'une analytics en temps réel, tout en limitant les coûts administratifs et de traitement.
Utilisez l'exécution de threads parallèles pour un chargement initial optimal.
Appliquez le partitionnement en fonction du temps et la cohérence transactionnelle pour sélectionner les transactions exécutées sur une certaine plage temporaire à traiter.

Générez des vues de données temps réel à faible latence et à moindre coût
Fusionnez les changements les plus récents encore non traités (y compris la dernière partition ouverte) dans une table, « on read ».
Optimisez le calcul en créant des vues en temps réel des data stores ODS et HDS, sans traiter les changements à chaque fois.

Générez des datasets dédiés à l'analytics à partir d'un data store historique (HDS) complet
Ajoutez automatiquement de nouvelles lignes au HDS, basées sur l'arrivée de données actualisées depuis des systèmes source.
Horodatez automatiquement les nouveaux enregistrements HDS pour créer une analyse des tendances et d'autres data marts analytiques axés sur le temps.
Prenez en charge des modèles de données incluant des dimensions à évolution lente (SDC) de type 2.

Les DataOps pour l'analytics
Obtenez des données en temps réel exploitables et prêtes à l'emploi pour tous les environnements d'analytics, de Qlik à Tableau, en passant par Power BI et bien d'autres.