







QLIK COMPOSE® PARA DATA LAKES
O caminho mais rápido para data lakes prontos para analytics

Automatize pipelines de dados prontos para analytics
Crie datasets prontos para analytics, automatizando a ingestão de dados, a criação de schema e atualizações contínuas.

PRINCIPAL RECURSO
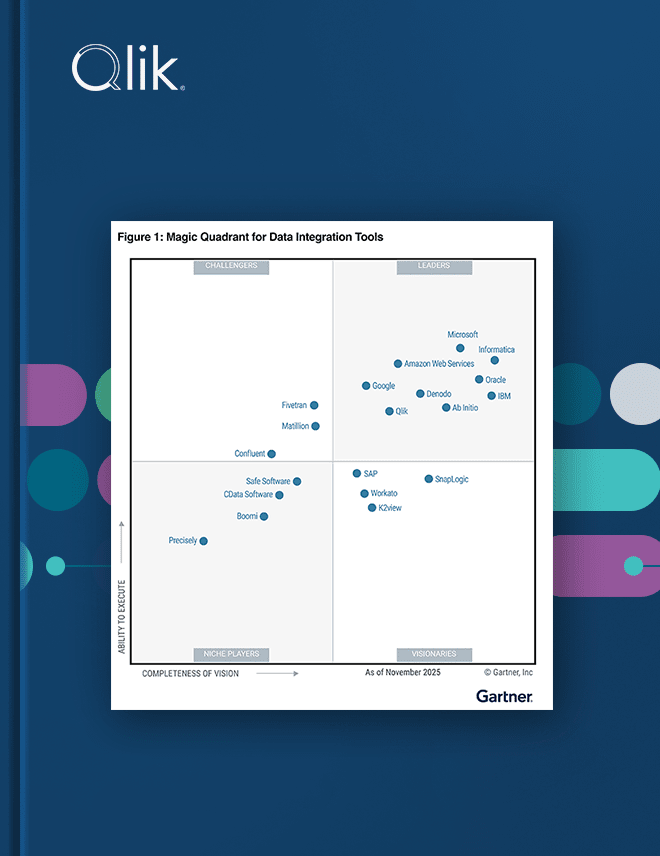
Gartner® Magic Quadrant™ 2025 para Ferramentas de Integração de Dados
Veja por que a Qlik® é Líder no Gartner Magic Quadrant para Ferramentas de Integração de Dados.

Facilidade de estruturação e transformação de dados
Construa, modele e execute pipelines de data lake com uma interface do usuário intuitiva e guiada
Gere schemas e estruturas de Hive Catalog automaticamente para armazenamentos de dados operacionais (ODS) e armazenamentos de dados históricos (HDS) sem codificação manual

Receba atualizações contínuas
Tenha certeza de que seu armazenamento de dados operacionais (ODS) e armazenamento de dados históricos (HDS) representem com precisão os sistemas de origem
Use change data capture (CDC) para permitir analytics em tempo real com menos sobrecarga administrativa e de processamento
Processe o carregamento inicial de forma eficiente com o threading paralelo
Garanta que apenas transações concluídas no período especificado sejam processadas, usando particionamento baseado em tempo e consistência transacional

Gere visualizações econômicas e de baixa latência de dados em tempo real
Mescle as últimas alterações não processadas na tabela de alterações (incluindo a última partição aberta) no Read.
Otimize a computação criando visualizações ao vivo, tanto de ODS quanto de HDS, sem precisar processar as alterações toda vez

Gere datasets específicos para analytics a partir de um armazenamento de dados históricos (HDS) completo
Acrescente novas linhas automaticamente ao HDS à medida que atualizações de dados chegam dos sistemas de origem
Registre automaticamente a data/hora de novos registros no HDS para criar análises de tendências e outros data marts analíticos orientados por tempo
Ofereça suporte a modelos de dados que incluem dimensões Tipo 2, que mudam lentamente

DataOps para analytics
Obtenha dados em tempo real, prontos para analytics e acionáveis em ambiente de analytics, de Qlik a Tableau, Power BI e muito mais.