







Qlik Compose for Data Lakes
Der schnellste Weg zu analysebereiten Data Lakes

Analysebereite Datenpipelines automatisieren
Erstellen Sie analysebereite Datensätze, indem Sie Datenerfassung, Schemaerstellung und kontinuierliche Updates automatisieren.

MUST-READ
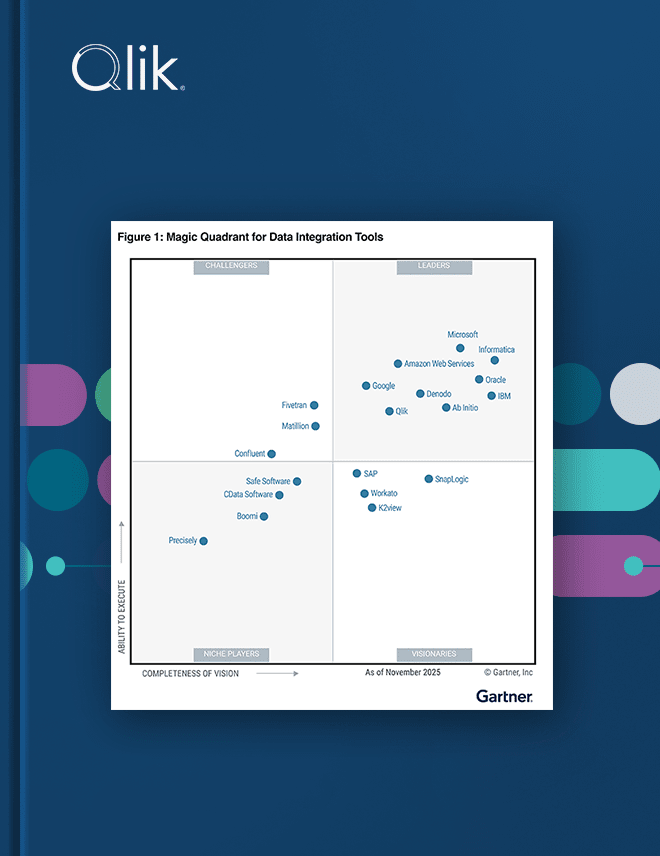
Gartner® Magic Quadrant™ for Data Integration Tools 2025
Lesen Sie, warum Qlik® im Gartner Magic Quadrant for Data Integration Tools als Leader eingestuft wurde.

Einfache Datenstrukturierung und -transformation
Nutzen Sie eine intuitive, geführte Benutzeroberfläche zum Einrichten, Modellieren und Ausführen Ihrer Data-Lake-Pipelines.
Generieren Sie automatisch Schemata und Hive-Katalogstrukturen für Betriebsdatenspeicher (ODS) und Historical Data Stores (HDS) ohne manuelle Programmierung.

Stets auf dem neuesten Stand
Sie können sicher sein, dass Ihre ODS und HDS Ihre Quellsysteme jederzeit korrekt abbilden.
Mit Change Data Capture (CDC) werden Echtzeitanalysen mit geringerem Administrations- und Verarbeitungsaufwand möglich.
Beim ersten Laden sorgt Multi-Threading für höchste Effizienz.
Nutzen Sie zeitbasierte Partitionierung mit transaktionaler Konsistenz, um ausschließlich Transaktionen zu verarbeiten, die innerhalb eines bestimmten Zeitraums abgeschlossen wurden.

Kostengünstige und latenzarme Ansichten von Live-Daten generieren
Führen Sie die letzten unverarbeiteten Änderungen in der Änderungstabelle (einschließlich der letzten offenen Partition) beim Lesen zusammen.
Optimieren Sie die Rechenleistung durch das Erstellen von Live-Ansichten – für ODS und HDS – ohne dass Änderungen jedes Mal verarbeitet werden müssen.

Analysespezifische Datensätze aus einem vollständigen HDS (Historical Data Store) generieren
Neue Zeilen werden automatisch an den HDS angefügt, sobald aktualisierte Daten aus den Quellsystemen eintreffen.
Die neuen HDS-Datensätze erhalten automatisch einen Zeitstempel. Das ermöglicht das Erstellen von Trendanalysen und anderen zeitorientierten Analyse-Data-Marts.
Datenmodelle mit Slowly Changing Dimensions (SCD) vom Typ 2 werden ebenfalls unterstützt.

DataOps for Analytics
Nutzen Sie analysebereite und direkt verwertbare Echtzeitdaten in Analyseumgebungen von Qlik bis Tableau, Power BI und mehr.