







QLIK COMPOSE® FOR DATA LAKES
La via più rapida ai data lake pronti per le analytics

Automatizza le pipeline di dati pronti per le analytics
Crea dataset pronti per le analytics automatizzando l'acquisizione di dati, la creazione di schemi e gli aggiornamenti continui.

RISORSA CHIAVE
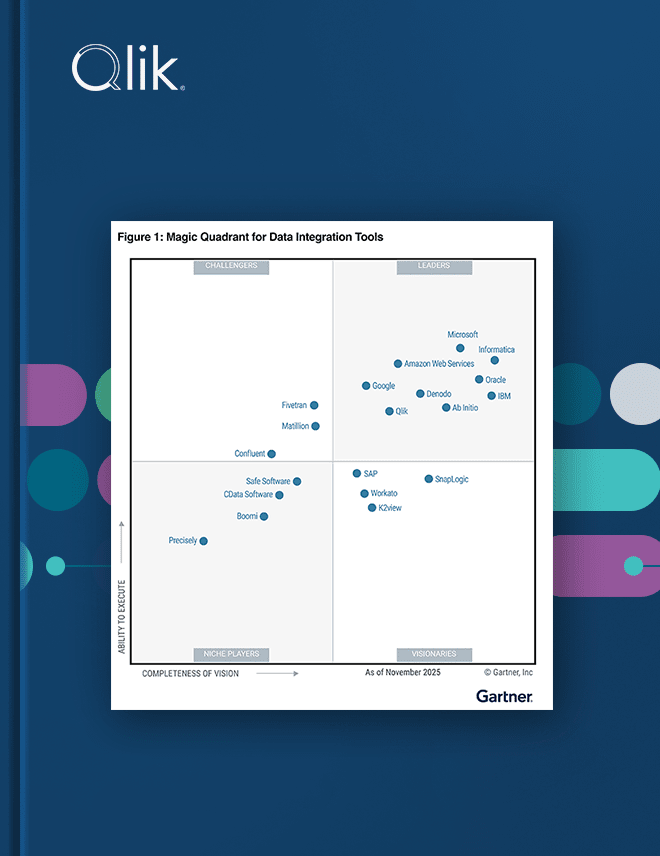
Gartner® Magic Quadrant™ 2025 per i tool di Data Integration
Scopri perché Qlik® è Leader nel Gartner® Magic Quadrant™ 2025 per i tool di Data Integration.

Facile strutturazione e trasformazione di dati
Costruisci, modella ed esegui pipeline di data lake con un'interfaccia utente guidata intuitiva
Genera automaticamente schemi e strutture di Hive Catalog per data store operativi (ODS) e data store storici (HDS) senza scrittura manuale di codice

Ottieni aggiornamenti continui
Assicurati con certezza che ODS e HDS rispecchino esattamente i sistemi sorgente
Usa il processo di acquisizione dei dati modificati (CDC) per abilitare analytics in tempo reale con una minore spesa di amministrazione ed elaborazione
Elabora in modo efficiente il caricamento iniziale con il threading parallelo
Assicurati che vengano elaborate solo le transazioni completate entro un tempo specificato, utilizzando le partizioni temporali e la coerenza transazionale

Genera viste di dati live a bassa latenza con costi ridotti
Integra le ultime modifiche non elaborate nella tabella delle modifiche (inclusa l'ultima partizione aperta) su Read.
Otimizza il calcolo creando viste live, sia per ODS sia per HDS, senza elaborare ogni volta le modifiche

Genera dataset specifici per le analytics da un data store storico (HDS) completo
Aggiungi automaticamente nuove righe all'HDS quando arrivano dati aggiornati dai sistemi sorgente
Aggiungi automaticamente una marca temporale ai nuovi archivi HDS per creare analisi dei trend e altri data mart analitici su base temporale
Supporta modelli di dati compreso Type-2, rallentando il cambiamento delle dimensioni

DataOps per l'analisi dei dati
Ottieni dati in tempo reale, pronti per le analytics e utilizzabili in qualsiasi ambiente di analisi, da Qlik a Tableau, fino a PowerBI e oltre.