Characteristics
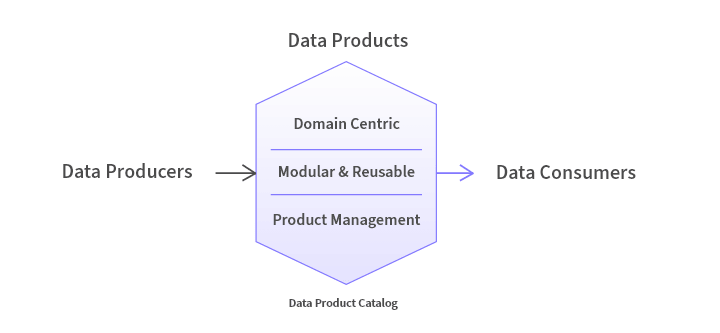
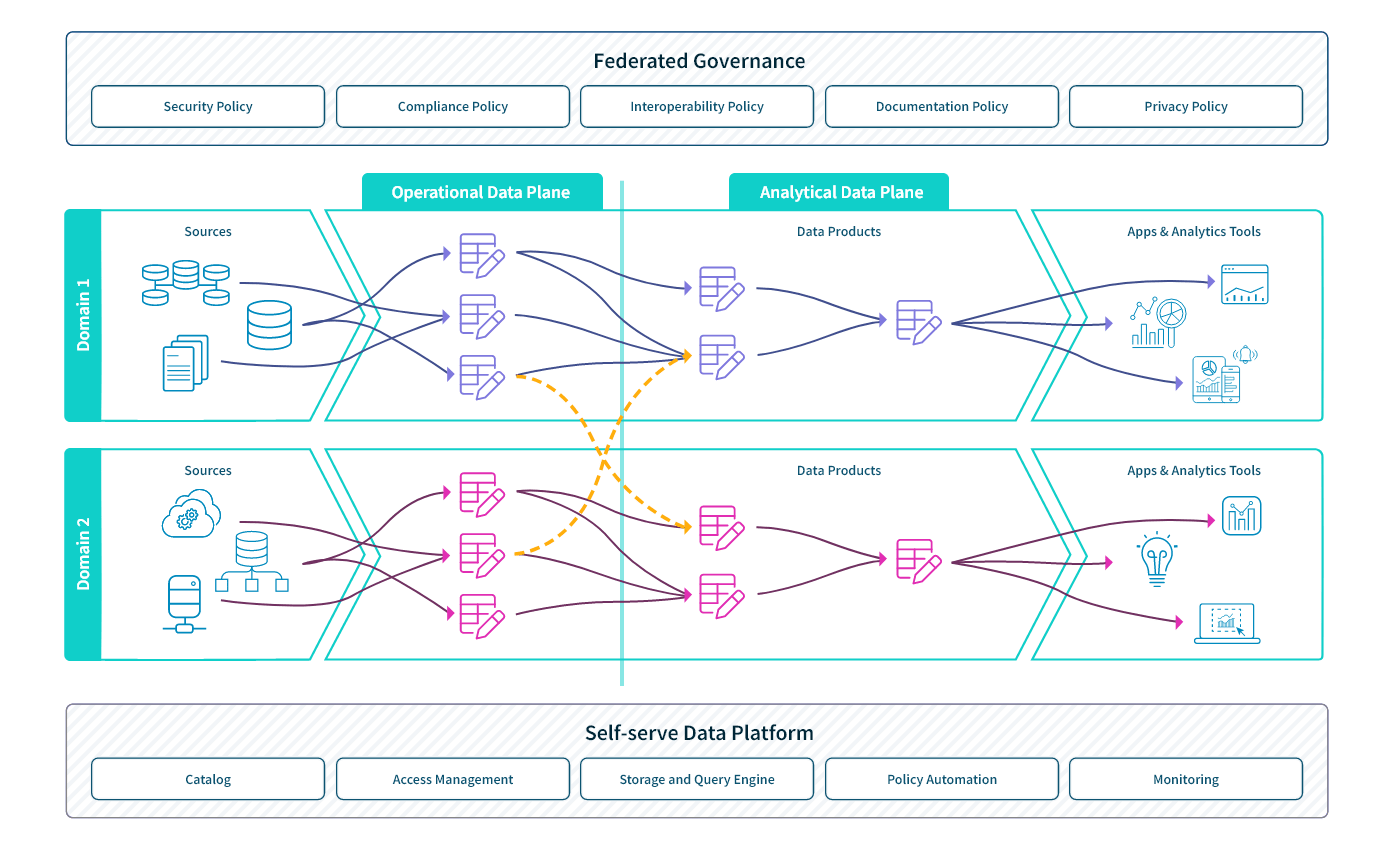
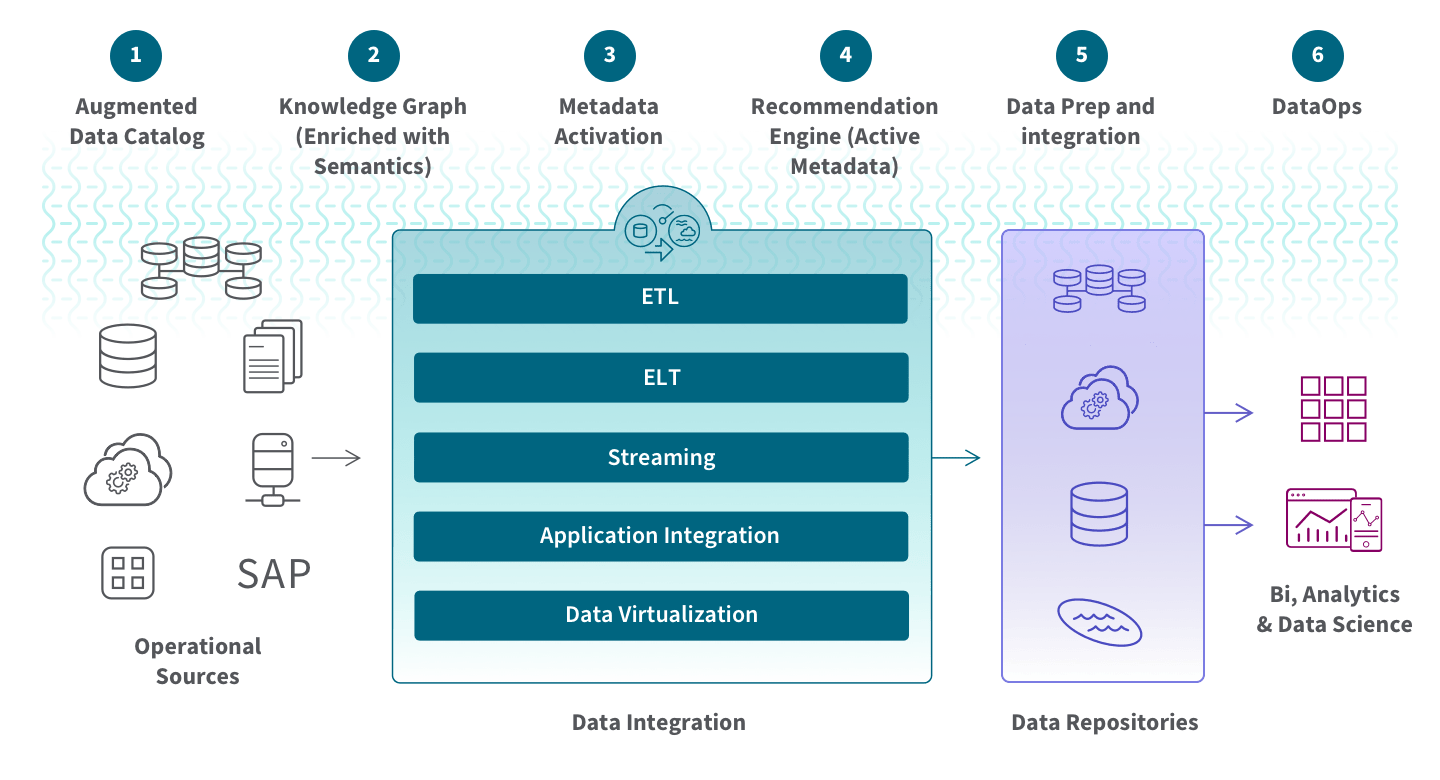
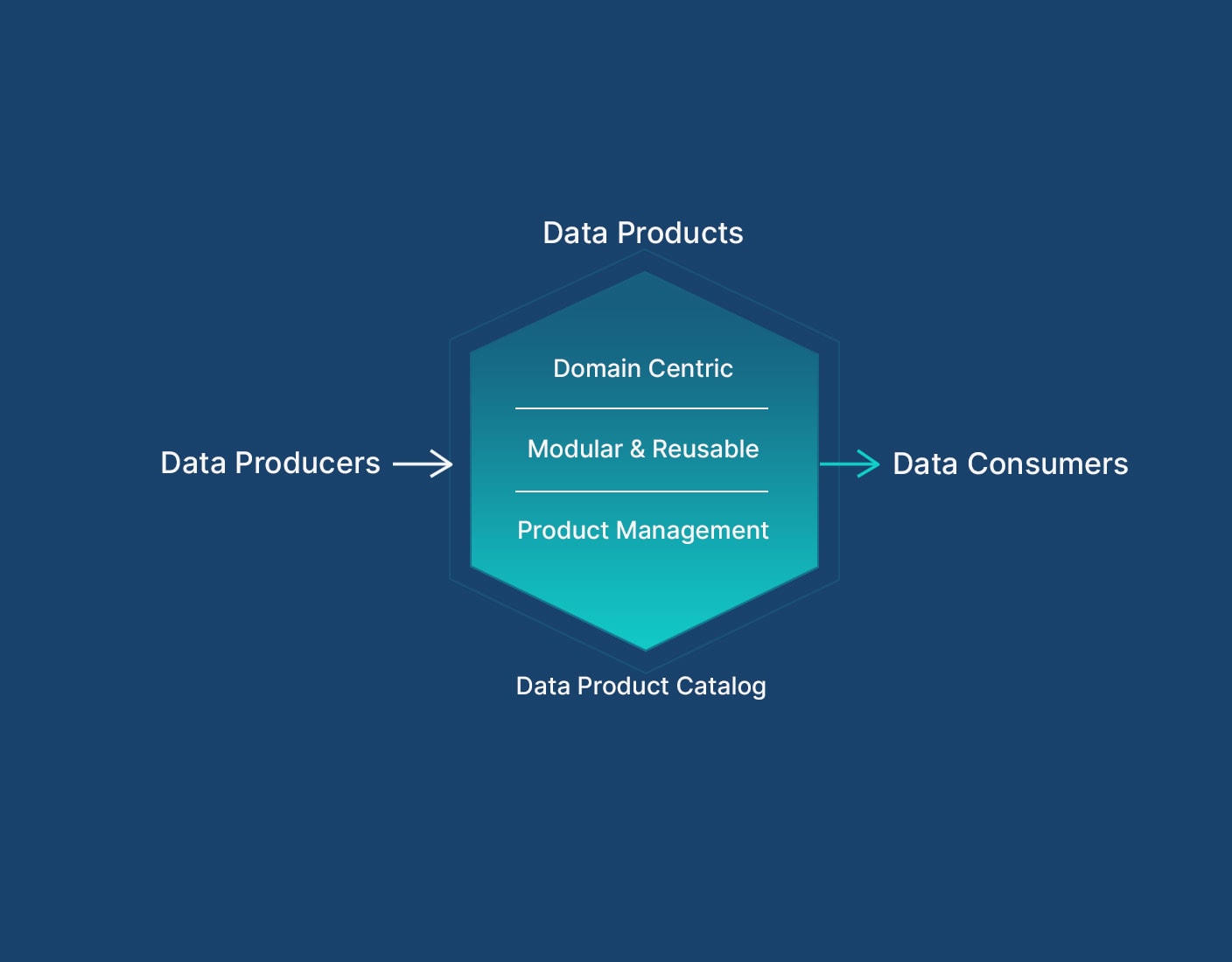
At a high level, a data product is a domain-specific, consumable entity aimed at transforming data into actionable insights for stakeholders and AI systems, enabling informed decision-making processes. The goal of data products is to make data accessible, consumable, insightful, and actionable for the increasing number of stakeholders and generative AI that rely on data to inform decision making. These products are created for a specific purpose and have defined and agreed-upon shapes, consumption interfaces, and maintenance and refresh cycles.
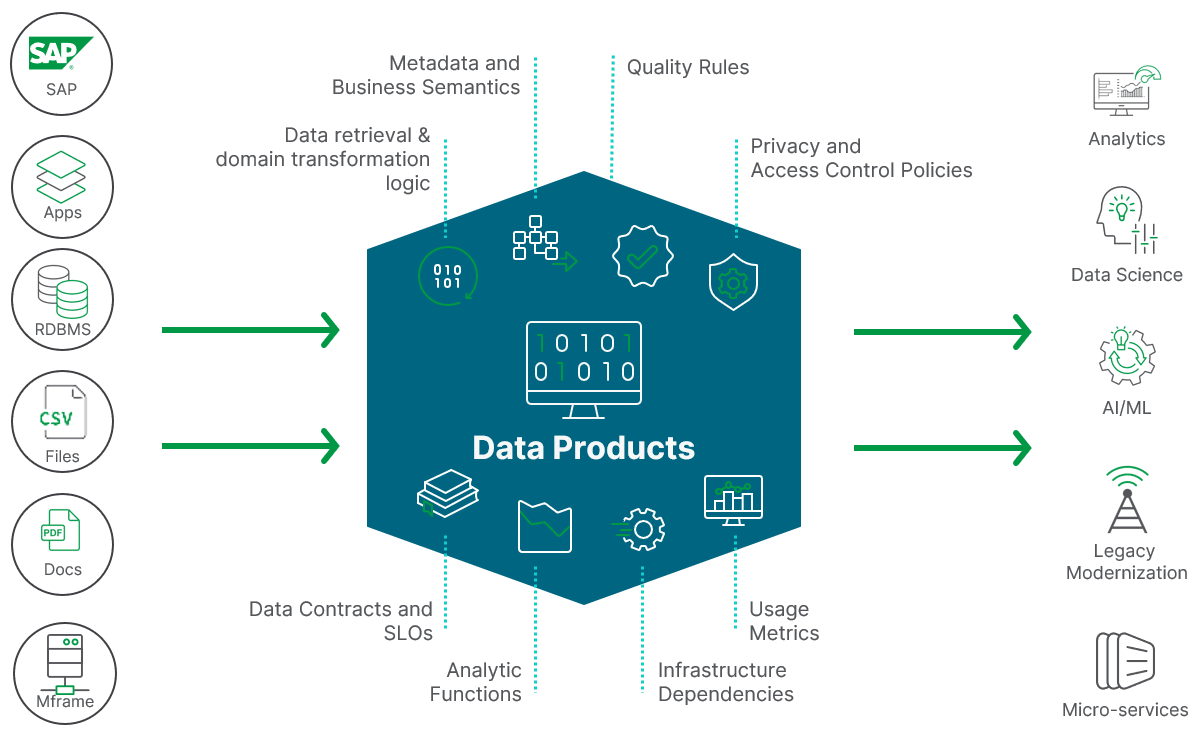
Essentially, data products are like self-contained containers that directly address business problems internal to an organization or are monetized externally. They leverage data analysis, processing, and visualization techniques to generate meaningful insights or support AI and machine learning, presenting them in a way that is easy to use.
Here are the 6 characteristics of a well-designed data product:
Prepared: Cleaned, transformed, high-quality data ready for analysis.
Findable and Understandable: Metadata-driven, domain-centric assets built for effective use.
Interoperable: Comprised of one or more datasets that work with each other to bring holistic, unbiased data insights.
Shareable: Several datasets and data elements packed into a single trusted cohesive unit, making it easy to distribute.
Accessible: Accessible to data consumers when needed in a standardized manner.
Reusable: Built of composable elements that can be used to build several data products, as well as derivative data products.