









































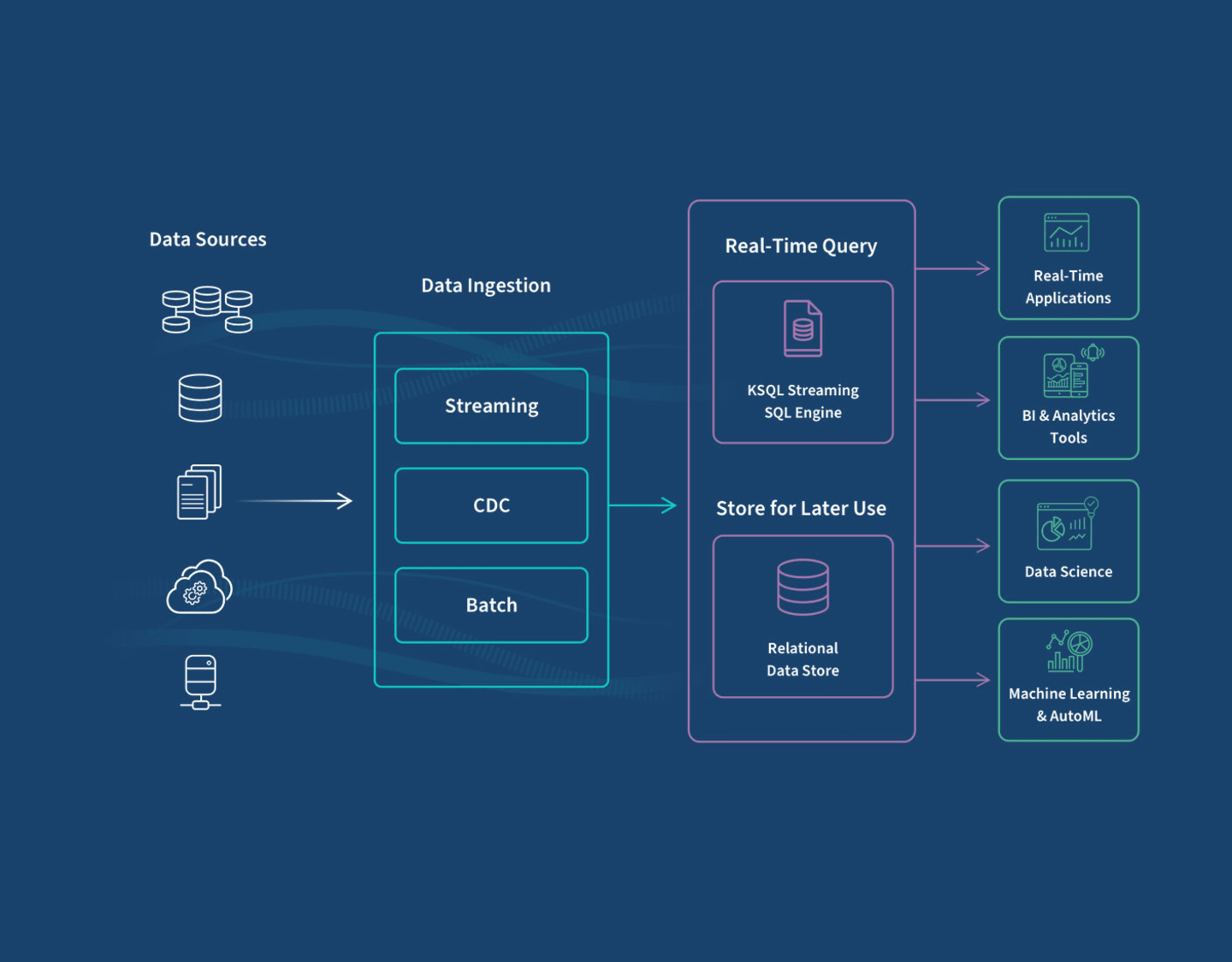
Types and Use Cases
Your unique business requirements and data strategy will determine which ingestion methods you choose for your organization. The primary factors involved in this decision are how quickly you need access to your data, and which data sources you’re using.
There are three main ways to ingest data: batch, real-time, and lambda, which is a combination of the first two.
Batch Processing
In batch-based processing, historical data is collected and transferred to the target application or system in batches. These batches can either be scheduled to occur automatically, can be triggered by a user query, or triggered by an application.
The main benefit of batch processing is that it enables complex analysis of large historical datasets. Also, traditionally, batch has been easier and less expensive to implement than real-time ingestion. But, modern tools are quickly changing this equation.
ETL pipelines support batch processing (ETL is an acronym for “Extract, Transform, and Load”). Converting raw data to match the target system before it is loaded, allows for systematic and accurate data analysis in the target repository.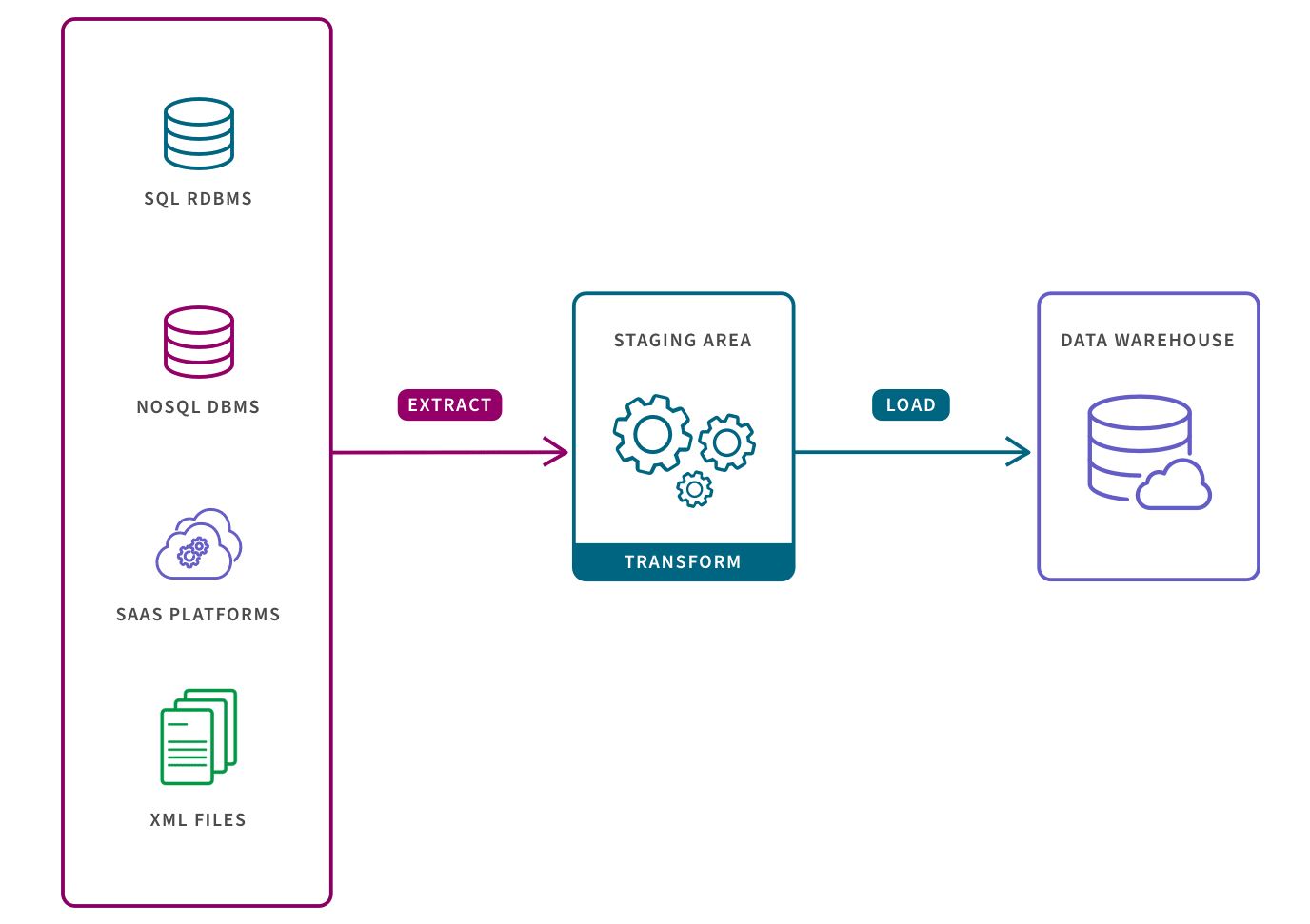
If you need timely, near real-time data but your data integration architecture prevents you from employing stream processing, micro batching is a good option to consider. Micro batching splits your data into groups and ingests them in very small increments, simulating real-time streaming. Apache Spark Streaming is actually a micro-batch processing extension of the Spark API.Real-Time Processing
In real-time processing, also known as stream processing, streaming pipelines move data continuously in real-time from source to target. Instead of loading data in batches, each piece of data is collected and transferred from source systems as soon as it is recognized by the ingestion layer.
A key benefit of stream processing is that you can analyze or report on your complete dataset, including real-time data, without having to wait for IT to extract, transform and load more data. You can also trigger alerts and events in other applications such as a content publishing system to make personalized recommendations or a stock trading app to buy or sell equities. Plus, modern, cloud-based platforms offer a lower cost and lower maintenance approach than batch-oriented pipelines.
For example, Apache Kafka is an open-source data store optimized for ingesting and transforming real-time streaming data. It’s fast because it decouples data streams, which results in low latency, and it’s scalable because it allows data to be distributed across multiple servers. Learn more about Apache Kafka.
Real-time data ingestion framework: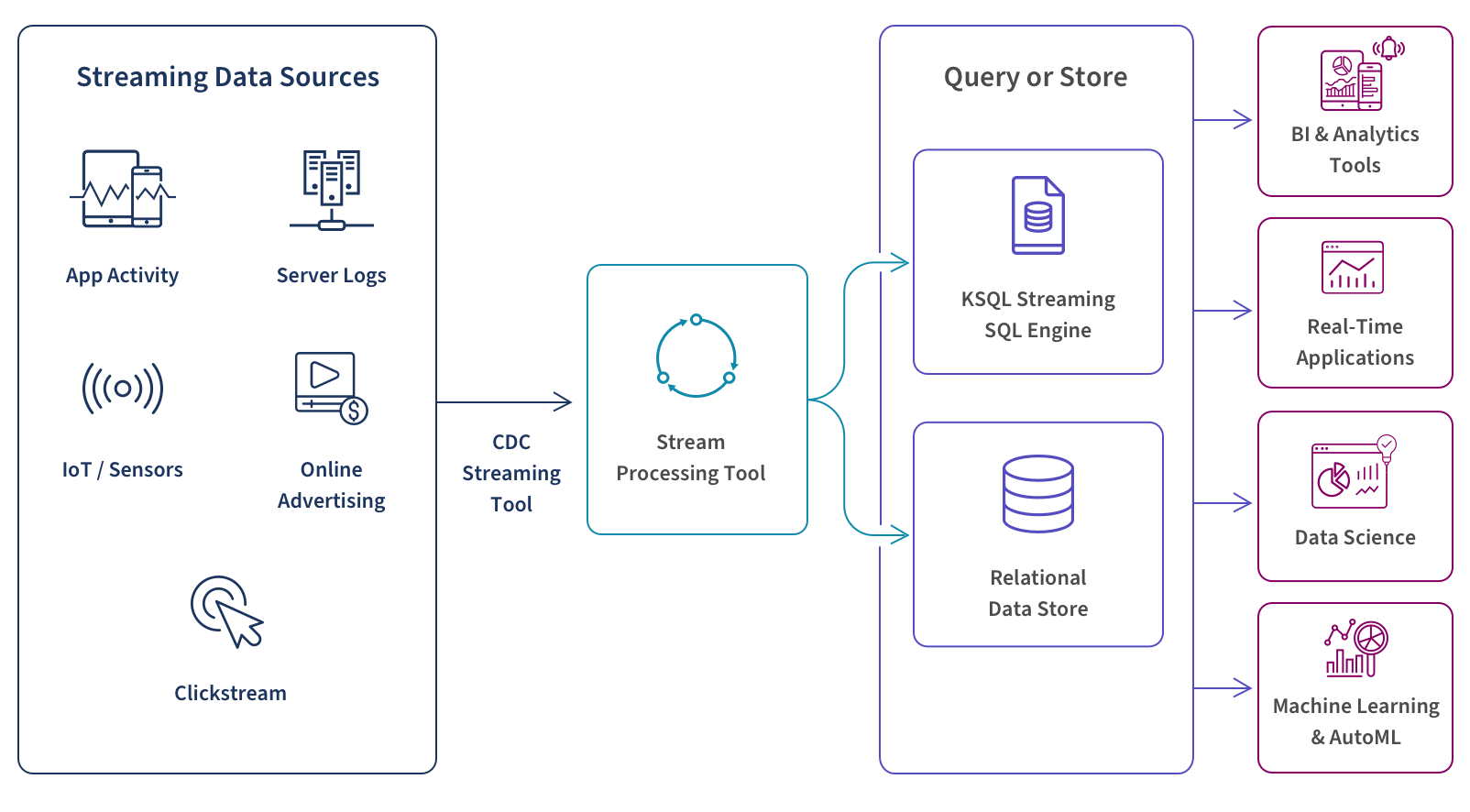
A CDC (change data capture) streaming tool allows you to aggregate your data sources and connect them to a stream processor. Your CDC tool should continually monitor transaction and redo logs and move changed data.
A tool such as Apache Kafka or Amazon Kinesis allows you to process your streaming data on a record-by-record basis, sequentially and incrementally or over sliding time windows.
Use a tool such as Snowflake, Google BigQuery, Dataflow, or Amazon Kinesis Data Analytics to filter, aggregate, correlate, and sample your data. This will allow you to perform real-time queries using a streaming SQL engine for Apache Kafka called ksqlDB. You can also store this data in the cloud for future use.
Now you can use a real-time analytics tool to conduct analysis, data science, and machine learning or AutoML without having to wait for data to reside in a database. And, as mentioned above, you can trigger alerts and events in other applications such as a content publishing system to make personalized recommendations to users or a stock trading app to buy or sell equities.
Lambda Architecture
Lambda architecture-based ingestion is a combination of both batch and real-time methods. Lambda consists of three layers. The first two layers, batch and serving, index your data in batches. The third layer, the speed layer, indexes in real-time any data that has not yet been ingested by the slower batch and serving layers. In this way, there is a continual balance between the three layers. This ensures that your data is both complete and available for you to query with minimal latency.
The benefit of this approach is that it brings you the best of both batch and real-time processing. It gives you the full view of your historical batch data while also reducing latency and eliminating the risk of data inconsistency.

